Java8一个很经典的版本,它的新特性有那些呢?
一.Lambda表达式
1.Lambda 表达式
Lambda 表达式,也可称为闭包,它是推动 Java 8 发布的最重要新特性。
Lambda 允许把函数作为一个方法的参数(函数作为参数传递进方法中)。
使用 Lambda 表达式可以使代码变的更加简洁紧凑。
在使用Lambda表达式之前先了解什么是函数式接口
函数式接口
-
只有函数式接口,才可以转换为lambda表达式
-
有且只有一个抽象方法的接口被称为函数式接口!
-
函数式接口可以显式的被@FunctionalInterface所表示,当被标识的接口不满足规定时,编译器会提示报错
-
同时只要接口只定义了一个抽象方法,那它就还是一个函数式接口,哪怕这个接口有好多默认的方法实现,如Comparator接口类
@FunctionalInterface`修饰函数式接口的,要求接口中的抽象方法只有一个。有多个抽象方法编译将报错
加不加@FunctionalInterface对于接口是不是函数式接口没有影响,该注解知识提醒编译器去检查该接口是否仅包含一个抽象方法
Runnable接口就是一个函数式接口

总结:
只要接口只定义了一个抽象方法,那它就是一个函数式接口,还有在上述Java Api中都有个@FunctionalInterface注解,这表示着该接口会设计成一个函数式接口,不符合规范的话,就会编译报错。
使用Lambda表达式的前提
对应接口有且只有一个抽象方法!!!(函数式接口)
- 创建一个新的线程来执行要执行的任务, 普通的匿名内部类实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
public class LambdaDemo01 {
public static void main(String[] args) {
functionOrdinary(); //调用普通的方法
}
public static void functionOrdinary() {
//开启一个新线程
new Thread(new Runnable() {
@Override
public void run() {
System.out.println("新线程的输出语句..." + Thread.currentThread().getName());
}
}).start();
System.out.println("主线程的输出语句..." + Thread.currentThread().getName());
}
}
代码分析:
- Thread类需要一个Runnable接口作为参数,其中的抽象方法run方法是用来指定线程任务内容的核心
- 为了指定run方法体,不得不需要Runnable的实现类
- 为了省去定义一个Runnable 的实现类,不得不使用匿名内部类
- 必须覆盖重写抽象的run方法,所有的方法名称,方法参数,方法返回值不得不都重写一遍,而且不能出错
- 而实际上,我们只在乎方法体中的代码
- 使用Lambda表达式
public class LambdaDemo01 {
public static void main(String[] args) {
// functionOrdinary(); //调用普通的方法
functionLambda(); //调用使用了Lambda的方法
}
public static void functionOrdinary() {
//开启一个新线程
new Thread(new Runnable() {
@Override
public void run() {
System.out.println("新线程的输出语句..." + Thread.currentThread().getName());
}
}).start();
System.out.println("主线程的输出语句..." + Thread.currentThread().getName());
}
public static void functionLambda() {
//开启一个新线程,使用Lambda表达式
new Thread(() -> {
System.out.println("新线程lambda表达式执行的语句..." + Thread.currentThread().getName());
}).start();
System.out.println("主线程的输出语句..." + Thread.currentThread().getName());
}
}
主要区别:
匿名内部类方式:
new Thread(new Runnable() {
@Override
public void run() {
System.out.println("新线程的输出语句..." + Thread.currentThread().getName());
}
}).start();
Lambda表达式方式:
new Thread(() -> {
System.out.println("新线程lambda表达式执行的语句..." + Thread.currentThread().getName());
}).start();
- Lambda表达式优点
- 简化了匿名内部类的使用, 语法更加的简单
2.Lambda表达式的语法
(parameters) -> expression (参数列表) -> 表达式 表达式-风格
或
(parameters) ->{ statements; } (参数列表) -> { 多条语句 } 块-风格
- 参数列表:其中 () 用来描述参数列表
- 箭头:
->为 lambda运算符 ,读作(goes to) , 作用是把参数列表和主体分隔为两个部分。 - 主体:{} 用来描述方法体, 当块中只有一条语句的时候可以省略
maskList.sort((Mask o1, Mask o2) -> o1.getBrand().compareTo(o2.getBrand()));

以下是lambda表达式的重要特征:
- 可选类型声明:不需要声明参数类型,编译器可以统一识别参数值。
- 可选的参数圆括号:一个参数无需定义圆括号,但多个参数和无参需要定义圆括号。
- 可选的大括号:如果主体包含了一个语句,就不需要使用大括号。
- 可选的返回关键字:如果主体只有一个表达式返回值则编译器会自动返回值,大括号需要指定表达式返回了一个数值。
// 1. 不需要参数,返回值为 5
() -> 5
// 2. 接收一个参数(数字类型),返回其2倍的值
x -> 2 * x
// 3. 接受2个参数(数字),并返回他们的差值
(x, y) -> x – y
// 4. 接收2个int型整数,返回他们的和
(int x, int y) -> x + y
// 5. 接受一个 string 对象,并在控制台打印,不返回任何值(看起来像是返回void)
(String s) -> System.out.print(s)
-
Demo01: 完成一个无参无返回的demo
直接打印输出
定义函数式接口: userService
@FunctionalInterface
public interface UserService {
void show();
}
在main方法中使用Lambda表达式:
public class LambdaDemo02 {
public static void main(String[] args) {
System.out.println("==================匿名内部类实现==================");
function(new UserService() {
@Override
public void show() {
System.out.println("匿名内部类实现方法....");
}
});
System.out.println("==================Lambda方式实现==================");
function(() -> {
System.out.println("Lambda表达式方法实现....");
});
function(() -> System.out.println("Lambda的最简写法..."));
}
public static void function(UserService userService) {
userService.show();
}
}
-
Demo02: 完成一个有两个参数有返回Demo
在List集合中保存多个Person对象,然后对这些对象做根据age排序操作
public class LambdaDemo03 {
public static void main(String[] args) {
List<Person> persons = new ArrayList<>();
persons.add(new Person("tom", 18));
persons.add(new Person("jack", 13));
persons.add(new Person("marry", 16));
persons.add(new Person("tony", 28));
persons.add(new Person("keb", 26));
//使用匿名内部类实现进行排序输出, 升序
Collections.sort(persons, new Comparator<Person>() {
@Override
public int compare(Person o1, Person o2) {
return o1.getAge() - o2.getAge();
}
});
//使用Lambda表达式实现, 降序
Collections.sort(persons, (o1, o2) -> o2.getAge() - o1.getAge());
//遍历输出
for (Person person : persons) {
System.out.println(person);
}
}
}
-
Demo03: 完成一个只有一个参数且有返回值的Demo
定义一个函数式接口PersonService
package com.abin.lambda.userService;
import com.abin.lambda.Entity.Person;
/**
* @author Abin
* @date 2022/01/19
*/
@FunctionalInterface
public interface PersonService {
Integer getPersonAge( Person person);
}
main方法中使用Lambda表达式
public class LambdaDemo04 {
public static void main(String[] args) {
Person person = new Person("张三", 19);
//使用匿名内部类的方式
Integer age = function(person, new PersonService() {
@Override
public Integer getPersonAge(Person person) {
return person.getAge();
}
});
System.out.println("age = " + age);
//使用Lambda表达式
Integer age1 = function(person, p -> p.getAge()); //这里的p 只是形参
System.out.println("age1 = " + age1);
Integer integer = function(person, Person::getAge); //方法引用
System.out.println(integer);
}
public static Integer function(Person person, PersonService personService) {
return personService.getPersonAge(person);
}
}
3.Lambda原理分析
匿名内部类的原理
匿名内部类的本质是在编译的时候产生一个.class的文件 XXXX$1.class 文件
可以使用反编译工具XJad查看编译时匿名内部类生成的代码:
// Decompiled by Jad v1.5.8e2. Copyright 2001 Pavel Kouznetsov.
// Jad home page: http://kpdus.tripod.com/jad.html
// Decompiler options: packimports(3) fieldsfirst ansi space
// Source File Name: LambdaDemo01.java
package com.abin.lambda;
import java.io.PrintStream;
// Referenced classes of package com.abin.lambda:
// LambdaDemo01
static class LambdaDemo01$1
implements Runnable
{
public void run()
{
System.out.println((new StringBuilder()).append("新线程的输出语句...").append(Thread.currentThread().getName()).toString());
}
LambdaDemo01$1()
{
}
}
Lambda表达式的实现原理
https://segmentfault.com/a/1190000023747150?utm_source=tag-newest
Lambda表达式的原理(写有lambda表达式的.class文件不能通过XJad查看)
我们可以通过JDK自带的工具javap对字节码文件进行反编译操作
1
2
3
javap -c -p filename.class
-c 表示对字节码文件进行反汇编
-p 表示显示所有的类和成员
对LambdaDemo01.class文件进行反汇编
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
javap -c -p LambdaDemo01.class
Compiled from "LambdaDemo01.java"
public class com.abin.lambda.LambdaDemo01 {
public com.abin.lambda.LambdaDemo01();
Code:
0: aload_0
1: invokespecial #1 // Method java/lang/Object."<init>":()V
4: return
public static void main(java.lang.String[]);
Code:
0: invokestatic #2 // Method functionLambda:()V
3: return
public static void functionLambda();
Code:
0: new #3 // class java/lang/Thread
3: dup
4: invokedynamic #4, 0 // InvokeDynamic #0:run:()Ljava/lang/Runnable;
9: invokespecial #5 // Method java/lang/Thread."<init>":(Ljava/lang/Runnable;)V
12: invokevirtual #6 // Method java/lang/Thread.start:()V
15: getstatic #7 // Field java/lang/System.out:Ljava/io/PrintStream;
18: new #8 // class java/lang/StringBuilder
21: dup
22: invokespecial #9 // Method java/lang/StringBuilder."<init>":()V
25: ldc #10 // String 主线程的输出语句...
27: invokevirtual #11 // Method java/lang/StringBuilder.append:(Ljava/lang/String;)Ljava/lang/StringBuilder;
30: invokestatic #12 // Method java/lang/Thread.currentThread:()Ljava/lang/Thread;
33: invokevirtual #13 // Method java/lang/Thread.getName:()Ljava/lang/String;
36: invokevirtual #11 // Method java/lang/StringBuilder.append:(Ljava/lang/String;)Ljava/lang/StringBuilder;
39: invokevirtual #14 // Method java/lang/StringBuilder.toString:()Ljava/lang/String;
42: invokevirtual #15 // Method java/io/PrintStream.println:(Ljava/lang/String;)V
45: return
private static void lambda$functionLambda$0();
Code:
0: getstatic #7 // Field java/lang/System.out:Ljava/io/PrintStream;
3: new #8 // class java/lang/StringBuilder
6: dup
7: invokespecial #9 // Method java/lang/StringBuilder."<init>":()V
10: ldc #16 // String 新线程lambda表达式执行的语句...
12: invokevirtual #11 // Method java/lang/StringBuilder.append:(Ljava/lang/String;)Ljava/lang/StringBuilder;
15: invokestatic #12 // Method java/lang/Thread.currentThread:()Ljava/lang/Thread;
18: invokevirtual #13 // Method java/lang/Thread.getName:()Ljava/lang/String;
21: invokevirtual #11 // Method java/lang/StringBuilder.append:(Ljava/lang/String;)Ljava/lang/StringBuilder;
24: invokevirtual #14 // Method java/lang/StringBuilder.toString:()Ljava/lang/String;
27: invokevirtual #15 // Method java/io/PrintStream.println:(Ljava/lang/String;)V
30: return
}
可以看到反编译的源码中看到生成了一个静态方法 ` private static void lambda$functionLambda$0();`
在Debug模式下查看lambda表达式的执行:
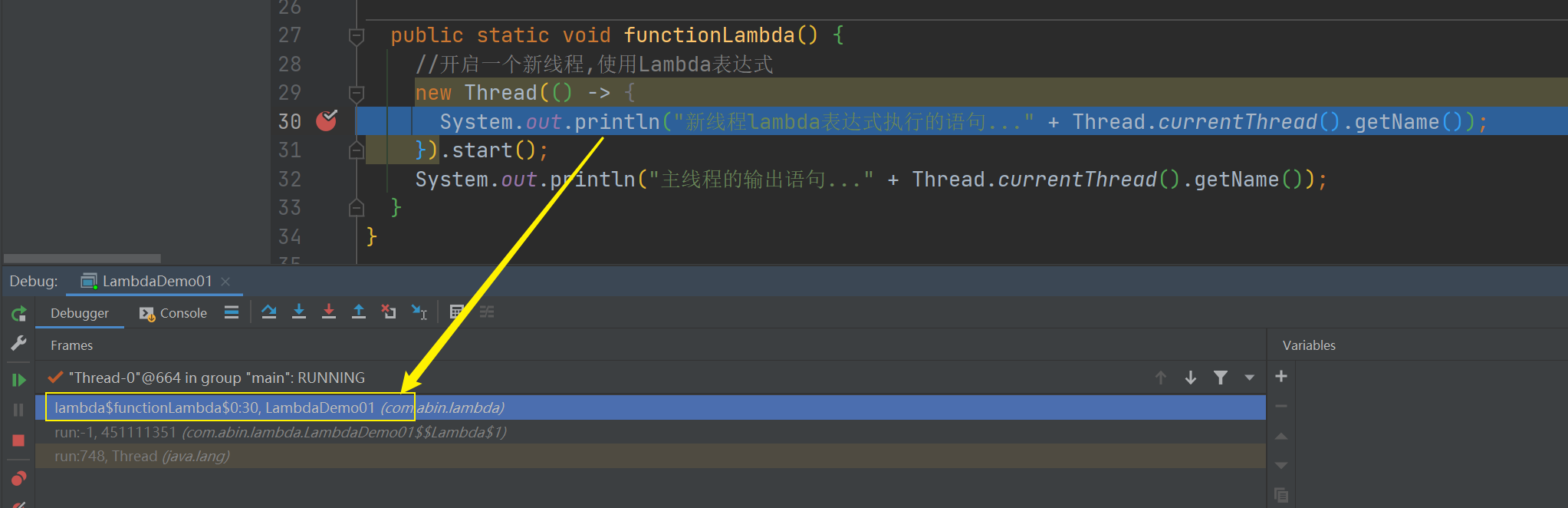
可以直观的看到方法体中的Lambda代码是在lambda$functionLambda$0方法中执行的
上面的效果可以理解为如下(可以这样理解):
public class LambdaDemo01 {
public static void main(String[] args) {
......
}
//可以这样理解为LambdaDemo01类中有lambda$functionLambda$0这么一个静态方法
private static void lambda$functionLambda$0() {
System.out.println("新线程lambda表达式执行的语句..." + Thread.currentThread().getName());
}
}
为了更加直观的理解这个内容, 在运行的时候添加-Djdk.internal.lambda.dumpProxyClasses参数, 作用是将内部的.class字节码输出到文件中
1
java -Djdk.internal.lambda.dumpProxyClasses 包名.类名
1
java -Djdk.internal.lambda.dumpProxyClasses com.abin.lambda.LambdaDemo01
这是在类文件中会生成一个LambdaDemo01$$Lambda$1.class的字节码文件
使用反编译工具XJad查看编译时候生成的代码:
// Decompiled by Jad v1.5.8e2. Copyright 2001 Pavel Kouznetsov.
// Jad home page: http://kpdus.tripod.com/jad.html
// Decompiler options: packimports(3) fieldsfirst ansi space
package com.abin.lambda;
// Referenced classes of package com.abin.lambda:
// LambdaDemo01
final class LambdaDemo01$$Lambda$1
implements Runnable
{
public void run()
{
LambdaDemo01.lambda$functionLambda$0();
}
private LambdaDemo01$$Lambda$1()
{
}
}
可以看到这个LambdaDemo01$$Lambda$1匿名内部类实现了Runnable接口,重写了 run() 方法, 然后在run()方法中调用了LambdaDemo01类中的生成的静态方法lambda$functionLambda$0(), 也就是调用了Lambda中的内容
总结 : 由此可以知道Lambda表达式,编译器在类中生成一个静态函数,运行时以内部类形式调用该静态函数。
本质上可以理解为如下代码:
public class LambdaDemo01 {
public static void main(String[] args) {
//开启一个新线程, 以匿名内部类的方式调用静态函数lambda$functionLambda$0
new Thread(new Runnable() {
@Override
public void run() {
LambdaDemo01.lambda$functionLambda$0();
}
}).start();
}
//可以这样理解为LambdaDemo01类中有lambda$functionLambda$0这么一个静态方法
private static void lambda$functionLambda$0() {
System.out.println("新线程lambda表达式执行的语句..." + Thread.currentThread().getName());
}
}
小结:
- 匿名内部类在编译的时候会生成一个xxx$1.class 的字节码文件
- Lambda表达式在运行的时候会形成一个类
- 在类中新增一个静态方法lambda$xxx$0(), 这个方法体内就是Lambda表达式中的代码
- 还会形成一个匿名内部类xxx$$Lambda$1, 实现接口, 重写接口中的抽象方法
- 在接口中重写的方法中调用新生成的静态方法lambda$xxx$0(), 也就执行了Lambda表达式中的代码
4.Lambda和匿名内部类的对比
- 所需类型不一样
- 匿名内部类的类型可以是 类,抽象类,接口
- Lambda表达式需要的类型必须是接口
- 抽象方法的数量不一样
- 匿名内部类所需的接口中的抽象方法的数量是随意的
- Lambda表达式所需的接口中只能有一个抽象方法
- 实现原理不一样
- 匿名内部类是在编译后形成一个class
- Lambda表达式是在程序运行的时候动态生成class
二.接口默认方法和静态方法
1. JDK8 中针对接口有增强.
在JDK8以前,接口中只能有静态常量和抽象方法
interface 接口名{
静态常量;
抽象方法;
}
而在JDK8以后对接口进行了增强, 接口中可以有默认方法和静态方法
interface 接口名{
静态常量;
抽象方法;
默认方法;
静态方法;
}
2.默认方法default
2.1 为什么增加默认方法
在JDK8以前接口中只能有静态常量和抽象方法,抽象方法不能有方法实现
public class InterfaceBoost {
public static void main(String[] args) {
AAA aaa = new AAA();
aaa.abstractFunc();
}
}
interface III {
public static final Integer number = 12; //静态常量
public void abstractFunc(); //抽象方法
}
class AAA implements III {
@Override
public void abstractFunc() {
System.out.println("实现类AAA中的重写的方法...");
}
}
class BBB implements III{
@Override
public void abstractFunc() {
}
}
问题: 这个接口中可以有多个抽象方法的, 当我们想去拓展接口增加抽象方法的时候, 所有的实现类都需要去重写这个新增的抽象方法 (这是一个很繁琐的事情, 例如JDK8中的Map接口中新增了一个forEach方法, 如果按原来的模式就必须在Map接口的164个实现类中都要重写这个forEach方法…)
2.2 JDK8之后接口的默认方法
接口中默认方法可以有默认方法体, 需要添加default关键字, 需要给出默认方法体, 作用是为了接口的拓展
接口中默认方法的语法格式是:
interface 接口名{
修饰符 default 返回类型 方法名(){
默认方法体;
}
}
public class InterfaceBoost {
public static void main(String[] args) {
AAA aaa = new AAA();
BBB bbb = new BBB();
aaa.abstractFunc();
aaa.defaultFunc();
bbb.defaultFunc();
}
}
interface III {
//接口中有些关键字可以省略
public static final Integer number = 12; //静态常量
public void abstractFunc(); //抽象方法
public default void defaultFunc(){ //默认方法: 添加关键字default
System.out.println("接口中的默认default方法");
}
}
//此时AAA类可以不用实现接口中存在的默认方法defaultFunc
class AAA implements III {
@Override
public void abstractFunc() {
System.out.println("实现类AAA中的重写的方法...");
}
}
class BBB implements III{
//也可以在实现类中重写接口中存在的默认方法
@Override
public void defaultFunc() {
III.super.defaultFunc();
System.out.println("实现类中重写接口中的默认方法...");
}
//必须实现这个abstractFunc抽象方法
@Override
public void abstractFunc() {
}
}
2.3 接口中默认方法的使用
接口中的默认方法有两种使用方式:
- 实现类中可以直接调用接口中的默认方法
- 实现类中可以重写接口中的默认方法
3.静态方法static
JDK8 中为接口新增了静态方法, 作用也是为了接口的拓展
3.1静态方法的语法
interface 接口名{
修饰符 static 返回类型 方法名称(){
方法体;
}
}
public class InterfaceBoost {
public static void main(String[] args) {
AAA aaa = new AAA();
//aaa.staticFunc(); 不能这样调用
III.staticFunc(); //接口中的静态方法只能通过接口来调用
}
}
interface III {
//接口中有些关键字可以省略
public static final Integer number = 12; //静态常量
public void abstractFunc(); //抽象方法
//接口中的默认方法, 添加关键字default
public default void defaultFunc(){
System.out.println("接口中的默认default方法");
}
//接口中的静态方法,添加关键字static,不能被实现类重写
public static void staticFunc(){
System.out.println("接口中的静态方法, 不能被实现类重写, 只能通过接口名.静态方法名调用");
}
}
class AAA implements III {
@Override
public void abstractFunc() {
System.out.println("实现类AAA中的重写的方法...");
}
}
3.2接口中的静态方法的使用
- 接口中的静态方法不能被实现类重写
- 调用的时候只能通过: 接口名.静态方法名 的方式来调用
4.接口中默认方法和静态方法的区别
- 接口默认方法通过 对象.默认方法名 调用, 接口静态方法通过 接口名.静态方法名 调用
- 实现类可以直接调用接口的默认方法, 也可以重写接口的默认方法
- 实现类不能重写接口的静态方法, 只能使用接口名调用
三.函数式接口
1.函数式接口的由来
使用Lambda表达式的前提是接口是函数式接口, 而Lambda表达式使用时不关心接口名, 抽象方法名. 只关心抽象方法的参数列表和返回值类型。因此为了让我们使用Lambda表达式更加的方法,在JDK中提供了大量常用的函数式接口
public class FuncInterface {
public static void main(String[] args) {
String str = "Hello World!";
String s = fun1(msg -> msg.toUpperCase(Locale.ROOT), str); //只关心传入的参数,和返回值
System.out.println(s);
}
public static String fun1(Operator operator, String argument){
return operator.handle(argument);
}
}
@FunctionalInterface
interface Operator{ //函数式接口
String handle(String s);
}
2.常用的函数式接口
在JDK8 中, 提供了一些函数式接口, 主要是在java.util.function包中, 主要作用是方便使用不用自己定义接口
2.1 Supplier
供应者: 无参有返回值接口 泛型是指定返回值的类型
get()方法
@FunctionalInterface
public interface Supplier<T> {
/**
* Gets a result.
*
* @return a result
*/
T get();
}
使用如下:
public class SupplierTest {
public static void main(String[] args) {
printMax(() -> {
int[] array = {41, 56, 69, 83, 38, 59};
Arrays.sort(array);
return array[array.length - 1];
});
}
public static void printMax(Supplier<Integer> supplier) { //这里的泛型Integer 是指定的返回类型
System.out.println("supplier.get() = " + supplier.get());
}
}
2.2 Consumer
消费者: 有参无返回接口 泛型是指定参数的类型
accept()方法
@FunctionalInterface
public interface Consumer<T> {
/**
* Performs this operation on the given argument.
*
* @param t the input argument
*/
void accept(T t);
/**
* Returns a composed {@code Consumer} that performs, in sequence, this
* operation followed by the {@code after} operation. If performing either
* operation throws an exception, it is relayed to the caller of the
* composed operation. If performing this operation throws an exception,
* the {@code after} operation will not be performed.
*
* @param after the operation to perform after this operation
* @return a composed {@code Consumer} that performs in sequence this
* operation followed by the {@code after} operation
* @throws NullPointerException if {@code after} is null
*/
default Consumer<T> andThen(Consumer<? super T> after) {
Objects.requireNonNull(after);
return (T t) -> { accept(t); after.accept(t); };
}
}
抽象方法accept的基本使用:
public class ConsumerTest {
public static void main(String[] args) {
String s = "Consumer接口的使用...";
funTest(arg -> {
System.out.println("arg = " + arg.toUpperCase(Locale.ROOT));
}, s);
}
public static void funTest(Consumer<String> consumer, String str) { //泛型是指定参数的类型
consumer.accept(str); //有参数,没有返回值
}
}
默认方法andThen的基本使用:
public class ConsumerAndThenTest {
public static void main(String[] args) {
String s = "Consumer接口的使用...";
funTest(arg -> {
System.out.println("arg = " + arg.toUpperCase(Locale.ROOT));
}, msg -> {
System.out.println("msg = " + msg.toLowerCase(Locale.ROOT));
}, s);
}
public static void funTest(Consumer<String> c1, Consumer<String> c2, String str) { //泛型是指定参数的类型
c1.accept(str); //步骤1
c2.accept(str); //步骤2
}
}
存在一步接一步的流程, 那么上面的代码可以修改为如下:
public class ConsumerAndThenTest {
public static void main(String[] args) {
String s = "Consumer接口的使用...";
funTest(arg -> {
System.out.println("arg = " + arg.toUpperCase(Locale.ROOT));
}, msg -> {
System.out.println("msg = " + msg.toLowerCase(Locale.ROOT));
}, s);
}
public static void funTest(Consumer<String> c1, Consumer<String> c2, String str) { //泛型是指定参数的类型
// c1.accept(str); //有参数,没有返回值
// c2.accept(str); //有参数,没有返回值
c1.andThen(c2).accept(str); //先执行c1然后再执行c2; 看源码理解
c2.andThen(c1).accept(str); //先执行c2然后再执行c1
}
}
Consumer的default方法andThen()的理解: (andThen然后)
如果一个方法的参数和返回值全部都是Consumer类型, 那么可以实现这样的效果: 消费一个数据的时候, 首先做一个操作,然后在做一个操作,实现组合, 这个方法就是Consumer接口中的default方法 andThen方法;
default Consumer<T> andThen(Consumer<? super T> after) {
Objects.requireNonNull(after);
return (T t) -> { accept(t); after.accept(t); };
}
2.3 Function
函数: 有参有返回的接口 Function接口是根据一个类型的数据得到另外一个类型的数据, 前者称为前置条件, 后者称为后置条件, 有参数也有返回值;
apply()方法
@FunctionalInterface
public interface Function<T, R> {
/**
* Applies this function to the given argument.
*
* @param t the function argument
* @return the function result
*/
R apply(T t);
}
基本使用:
public class FunctionTest {
public static void main(String[] args) {
function(arg -> arg.length(), "hello"); //返回字符串的长度
}
public static void function(Function<String, Integer> function, String str) {
Integer apply = function.apply(str);
System.out.println("apply = " + apply); //打印字符串的长度
}
}
Function的andThen方法: ` f1.andThen(f2).apply(str); `//先执行f1, 然后在执行f2;
public class FunctionAndThenTest {
public static void main(String[] args) {
function(arg -> {
int length = arg.length();
System.out.println(length);
return length;
}, msg -> msg * 10, "hello world");
}
public static void function(Function<String, Integer> f1, Function<Integer, Integer> f2,
String str) {
Integer apply = f1.andThen(f2).apply(str); //先执行f1, 然后在执行f2;
System.out.println("apply = " + apply);
}
}
Function的默认compose方法: ` f1.compose(f2).apply(str); ` // 是先执行f2, 然后在执行f1;
public class FunctionAndThenTest {
public static void main(String[] args) {
function(arg -> {
int length = arg.length();
System.out.println(length);
return length;
}, msg -> msg * 10, "hello world");
}
public static void function(Function<String, Integer> f1, Function<Integer, Integer> f2,
String str) {
// Integer apply = f1.andThen(f2).apply(str); //先执行f1, 然后在执行f2;
// 默认方法compose和andThen的执行顺序是刚好相反的
Integer apply = f2.compose(f1).apply(str); // 同样的是先执行f1, 然后在执行f2;
System.out.println("apply = " + apply);
}
}
Function接口的andThen方法源码:
default <V> Function<T, V> andThen(Function<? super R, ? extends V> after) {
Objects.requireNonNull(after);
return (T t) -> after.apply(apply(t));
}
Function接口的compose方法源码:
default <V> Function<V, R> compose(Function<? super V, ? extends T> before) {
Objects.requireNonNull(before);
return (V v) -> apply(before.apply(v));
}
可以看到默认方法andThen默认方法compose的执行顺序刚好相反
Function接口中还有一个静态方法identity: 作用是传入的什么参数就返回什么参数, 源码如下
static <T> Function<T, T> identity() {
return t -> t;
}
2.4 Predicate
有参返回boolean类型的接口 作用是接受一个参数,返回boolean类型的值
test()方法
@FunctionalInterface
public interface Predicate<T> {
/**
* Evaluates this predicate on the given argument.
*
* @param t the input argument
* @return {@code true} if the input argument matches the predicate,
* otherwise {@code false}
*/
boolean test(T t);
使用:
public class PredicateTest {
public static void main(String[] args) {
function(arg -> {
boolean equals = arg.equals(1000);
return equals;
});
}
public static void function(Predicate<Integer> pred) {
System.out.println("pred.test(100) = " + pred.test(100));
}
}
Predicate接口中的and方法使用:
public class PredicateDefaultTest {
public static void main(String[] args) {
function(n1 -> n1 >= 60, n2 -> n2 <= 100, 80);
}
public static void function(Predicate<Integer> p1, Predicate<Integer> p2, Integer s) {
// s 同时满足p1,p2;
if (p1.and(p2).test(s)) {
System.out.println("成绩合格");
} else {
System.out.println("成绩不合格");
}
}
}
在Predicate接口中提供了很多的默认方法, 逻辑处理 and , or , negate , isEqual 方法
源码如下:
package java.util.function;
import java.util.Objects;
@FunctionalInterface
public interface Predicate<T> {
boolean test(T t);
//and
default Predicate<T> and(Predicate<? super T> other) {
Objects.requireNonNull(other);
return (t) -> test(t) && other.test(t);
}
//negate
default Predicate<T> negate() {
return (t) -> !test(t);
}
//or
default Predicate<T> or(Predicate<? super T> other) {
Objects.requireNonNull(other);
return (t) -> test(t) || other.test(t);
}
//isEqual
static <T> Predicate<T> isEqual(Object targetRef) {
return (null == targetRef)
? Objects::isNull
: object -> targetRef.equals(object);
}
}
四.方法引用
Java8 方法引用的细节: https://www.cnblogs.com/xiaoxi/p/7099667.html
1.方法引用的由来
使用普通的lambda表达式有时候也会很显得冗余
public class FunctionRefTest01 {
// TODO: 2022/1/21 计算数组的和
public static void main(String[] args) {
int[] array = {10, 20, 30};
getSum(arg -> {
int sum = 0;
for (int item : arg) {
sum += item;
}
return sum;
}, array);
}
public static void getSum(Function<int[], Integer> function, int[] array) {
Integer sum = function.apply(array);
System.out.println("sum = " + sum);
}
}
方法引用是用来直接访问类或者实例的已经存在的方法或者构造方法
public class FunctionRefTest02 {
public static void main(String[] args) {
getTotal(FunctionRefTest02::getSum); //方法引用
}
public static void getSum(int[] array) {
int sum = 0;
for (int item : array) {
sum += item;
}
System.out.println("sum = " + sum);
}
public static void getTotal(Consumer<int[]> consumer) {
int[] array = {10, 20, 30};
consumer.accept(array);
}
}
2.方法引用的概述
方法引用(Method References)
-
当要传递给Lambda体的操作,已经有了实现方法,可以使用方法引用。
-
方法引用是用来直接访问类或者实例的已经存在的方法或者构造方法。
-
方法引用提供了一种引用而不执行方法的方式,它需要由兼容的函数式接口构成的目标类型上下文。计算时,方法引用会创建函数式接口的一个实例。
- 当Lambda表达式中只是执行一个方法调用时,不用Lambda表达式,直接通过方法引用的形式可读性更高一些。
-
方法引用是一种更简洁易懂的Lambda表达式。
- 注意方法引用是一个Lambda表达式,其中方法引用的操作符是双冒号”::”。
常见的方法引用方式
- instanceName::methodName 对象::方法名
- ClassName::staticmethodName 类名::静态方法名
- ClassName::methodName 类名::普通方法名
- ClassName::new 类名::new 调用的构造器
- TypeName[]::new String[]::new 调用数组的构造器
| 方法引用类别 | 举例 |
|---|---|
| 引用静态方法 | Integer::sum |
| 引用某个对象的方法 | list::add |
| 引用某个类的方法 | String::length |
| 引用构造方法 | HashMap::new |
2.1 对象名::方法名
这是最常用的方法, 如果一个类中已经存在了一个成员方法, 则可以通过对象名::方法名调用
public class FunctionRefTest03 {
public static void main(String[] args) {
Date now = new Date();
//使用lambda表达式
Supplier<Long> supplier = ()-> now.getTime();
System.out.println("supplier = " + supplier.get());
//使用方法引用 对象::方法名
Supplier<Long> supplier1 = now::getTime;
System.out.println("supplier1 = " + supplier1.get());
}
}
方法引用的注意事项:
- 被引用的方法, 参数要和接口中的抽象方法的参数一致
- 当接口的抽象方法有返回值的时候, 被引用的方法也必须要有返回值
2.2 类名::静态方法名
这个写法也是比较常用的
public class FunctionRefTest04 {
public static void main(String[] args) {
//使用lambda表达式
Supplier<Long> currentTime = ()->System.currentTimeMillis();
System.out.println("currentTime.get() = " + currentTime.get());
//使用方法引用 类名::静态方法名
Supplier<Long> currentTime1 = System::currentTimeMillis;
System.out.println("currentTime1.get() = " + currentTime1.get());
}
}
2.3 类名::普通方法名
Java面向对象中, 类名只能调用静态方法, 类名引用示例方法是有前提的, 实际上类名::普通方法名是拿第一个参数作为方法的调用者;
public class FunctionRefTest05 {
public static void main(String[] args) {
Function<String, Integer> function = (s -> s.length());
System.out.println("function.apply(\"hello\") = " + function.apply("hello"));
//使用方法引用, 类名::普通方法名 其实是用第一个参数作为方法的调用者
Function<String, Integer> function1 = (String::length);
System.out.println("function1.apply(\"str\") = " + function1.apply("str"));
//两个参数一个返回值使用BiFunction
BiFunction<String, String, String> biFunction = String::concat;
String apply = biFunction.apply("hello ", "world");
System.out.println("apply = " + apply);
}
}
2.4 类名::构造器
由于构造器的名称和类名完全一致, 所有构造器引用使用类名::new
public class FunctionRefTest06 {
public static void main(String[] args) {
Supplier<Person> supplier = () -> new Person();
System.out.println("supplier.get() = " + supplier.get());
//使用方法引用 类名::new 返回一个对象
Supplier<Person> p = Person::new;
System.out.println("p.get() = " + p.get());
//使用全参构造器的方法引用
BiFunction<String, Integer, Person> personBiFunction = Person::new;
Person person = personBiFunction.apply("小明", 18);
System.out.println("person = " + person);
}
}
2.5 数组[]::构造器
使用方法引用构造一个数组:
public class FunctionRefTest07 {
public static void main(String[] args) {
Function<Integer, String[]> function = (n) -> {
return new String[n];
};
String[] apply1 = function.apply(5);
System.out.println("apply1.length = " + apply1.length);
//使用方法引用 类型类名[]::new 返回一个数组
Function<Integer, String[]> func = String[]::new;
String[] apply = func.apply(10);
System.out.println("apply.length = " + apply.length);
}
}
小结
- 方法引用是对lambda表达式符合特定情况下的一种缩写形式, 可以使得lambda表达式更加精简
- 不过要注意方法引用只能引用已经存在的方法
五.Stream流 API
Java8 Stream: https://blog.csdn.net/mu_wind/article/details/109516995
深入理解Java函数式编程: https://www.cnblogs.com/CarpenterLee/category/965121.html
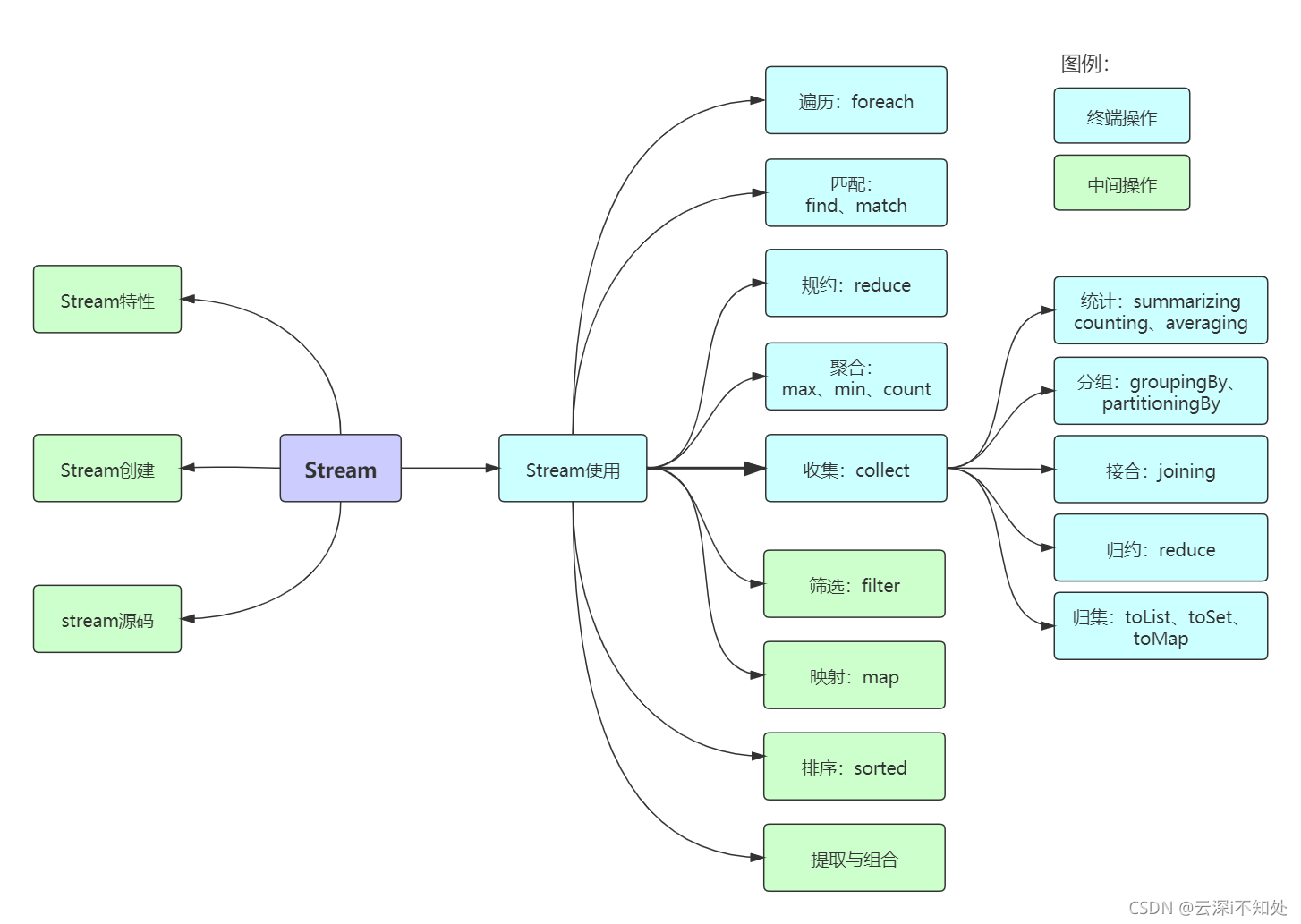
1. 集合处理数据的弊端
当我们在需要对集合中的元素进行操作的时候,除了必需的添加,删除,获取外,最典型的操作就是集合遍历
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
public class StreamTest01 {
public static void main(String[] args) {
List<String> list = Arrays.asList("张三", "张三丰", "小明", "佩奇", "爱迪生", "张培培");
List<String> tempList = new ArrayList<>();
//获取姓张的用户
for (String s : list) {
if (s.startsWith("张")){
tempList.add(s);
}
}
ArrayList<String> tempList2 = new ArrayList<>();
//获取名称长度为3的用户
for (String s : tempList) {
if(s.length() == 3){
tempList2.add(s);
}
}
//遍历输出
for (String s : tempList2) {
System.out.println("s = " + s);
}
}
}
上面的代码也可以实现想要的功能, 但是存在诸多问题: 只要操作数据就要进行遍历, 只要操作就要for循环,而且还要定义很多的中间的集合容器. 代码是比较冗余的, 而Java8中的stream可以解决这些问题
public class StreamTest01 {
public static void main(String[] args) {
List<String> list = Arrays.asList("张三", "张三丰", "小明", "佩奇", "爱迪生", "张培培");
//使用Java8中的stream流
list.stream()
.filter(s -> s.startsWith("张"))
.filter(s->s.length() == 3)
.forEach(System.out::println);
}
}
上面的streamAPI的含义: 获取流, 过滤”张”, 过滤长度, 逐一打印, 代码相比于前面更加简洁直观
2.Stream流式思想概述
- Stream和IO流 (inputstream/outputstream) 没有任何关系,请暂时忘记对传统IO流的固有印象.
- Stream流式思想类似于工厂车间的“生产流水线”, 只对数据进行处理.
- Stream流不是一种数据结构,不保存数据,而是对数据进行加工处理.
- Stream可以看作是流水线上的一个工序。在流水线上,通过多个工序让一个原材料加工成一个商品.
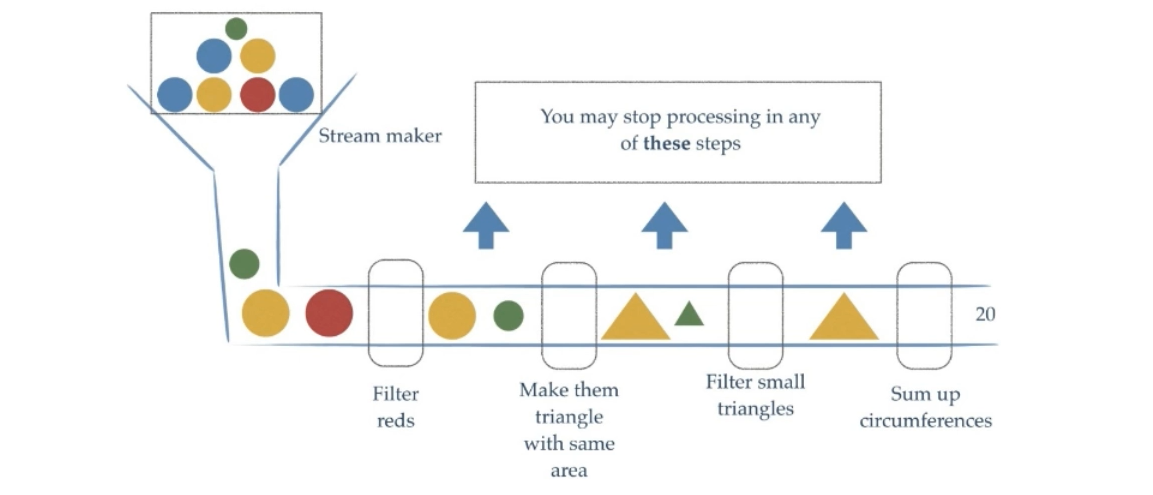
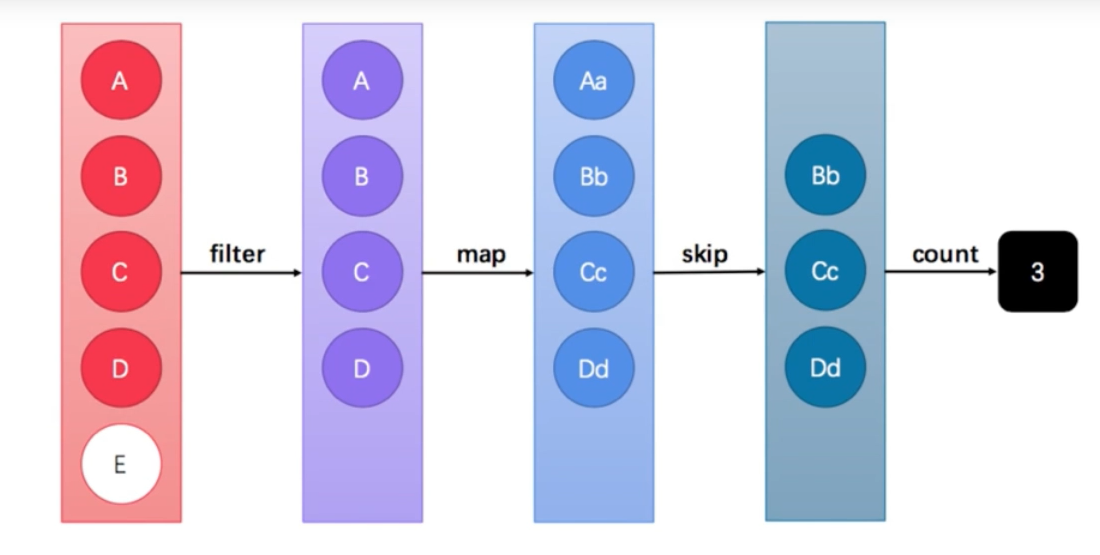
stream API 能让我们快速完成许多复杂的操作, 如筛选, 切片, 映射, 查找, 去重, 统计, 匹配和归约等操作
3.Stream流的获取方法
3.1根据Collocation获取
首先, java.util.Collection接口中加入了default方法stream, 则说明实现了Collocation接口的集合都可以使用.stream()方式获取Stream流
public class StreamTest02 {
public static void main(String[] args) {
//实现了Collocation接口的集合都可以使用.stream()方式获取流
ArrayList<String> arrayList = new ArrayList<>();
Stream<String> stream = arrayList.stream();
HashSet<String> hashSet = new HashSet<>();
Stream<String> stream1 = hashSet.stream();
Vector<Integer> vector = new Vector<>();
Stream<Integer> stream2 = vector.stream();
}
}
但是Map集合没有实现Collocation接口, 所以Map集合不能直接获取Stream流, 这时怎么办呢, 可以根据Map集合获取相应的 Key Value 的集合.
public class StreamTest03 {
public static void main(String[] args) {
HashMap<String, String> hashMap = new HashMap<>();
Set<String> keySet = hashMap.keySet();
Stream<String> stream = keySet.stream();
Collection<String> values = hashMap.values();
Stream<String> stream1 = values.stream();
Set<Entry<String, String>> entrySet = hashMap.entrySet();
Stream<Entry<String, String>> stream2 = entrySet.stream();
}
}
3.2通过Stream的of方法
在实际开发过程中, 不可避免的使用数组, 由于数组对象不可能添加默认方法, 所以在Stream接口中提供了一个static静态方法of()方法, 可以获取数组对象的Stream流, 但是需要注意: 使用数组对象的时候不能使用基本类型的数组
public static void main(String[] args) {
//当在实际操作过程中, 如果只对数组进行操作, 怎么将数组转化为Stream?
Stream<String> stream = Stream.of("s1", "s2", "s3", "s4");
String[] array = {"tom", "jack", "marry"};
Stream<String> stream1 = Stream.of(array);
Integer[] arr = {1, 2, 3, 4, 5};
Stream<Integer> stream2 = Stream.of(arr);
stream2.forEach(System.out::println);
//注意, 使用Stream.of()方法的时候,只能使用包装类, 不能使用基本数据类型
int[] arrays = {55, 66, 77, 88};
Stream<int[]> stream3 = Stream.of(arrays); // 不能使用基本数据类型, 基本数据类型的数据是不行的
stream3.forEach(System.out::println);
}
}
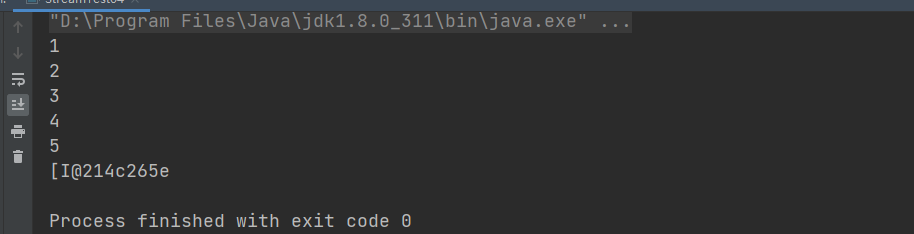
虽然大部分情况下stream是容器调用Collection.stream()方法得到的,但stream和collections有以下不同:
- 无存储。stream不是一种数据结构,它只是某种数据源的一个视图,数据源可以是一个数组,Java容器或I/O channel等。
- 为函数式编程而生。对stream的任何修改都不会修改背后的数据源,比如对stream执行过滤操作并不会删除被过滤的元素,而是会产生一个不包含被过滤元素的新stream。
- 惰式执行。stream上的操作并不会立即执行,只有等到用户真正需要结果的时候才会执行。
- 可消费性。stream只能被“消费”一次,一旦遍历过就会失效,就像容器的迭代器那样,想要再次遍历必须重新生成。
4.Stream常用方法
Stream可以由数组或集合创建,对流的操作分为两种:
-
中间操作,每次返回一个新的Stream,支持链式调用。
-
终端操作,每个流只能进行一次终端操作,终端操作结束后流无法再次使用。也不支持链式调用, 终端操作会产生一个新的集合或值。
另外,Stream有几个特性:
- stream不存储数据,而是按照特定的规则对数据进行计算,一般会输出结果。
- stream不会改变数据源,通常情况下会产生一个新的集合或一个值。
- stream具有延迟执行特性,只有调用终端操作时,中间操作才会执行。
对stream的操作分为为两类,中间操作(intermediate operations)和结束操作(terminal operations),二者特点是:
- 中间操作总是会惰式执行,调用中间操作只会生成一个标记了该操作的新stream,仅此而已。
- 结束操作会触发实际计算,计算发生时会把所有中间操作积攒的操作以pipeline的方式执行,这样可以减少迭代次数。计算完成之后stream就会失效。
如果你熟悉Apache Spark RDD,对stream的这个特点应该不陌生。
下表汇总了Stream接口的部分常见方法:
| 操作类型 | 接口方法 |
|---|---|
| 中间操作 | concat() distinct() filter() flatMap() limit() map() peek() skip() sorted() parallel() sequential() unordered() |
| 结束操作 | allMatch() anyMatch() collect() count() findAny() findFirst() forEach() forEachOrdered() max() min() noneMatch() reduce() toArray() |
区分中间操作和结束操作最简单的方法,就是看方法的返回值,返回值为stream的大都是中间操作,否则是结束操作。
4.1 forEach
forEach方法是用来遍历流中的数据的 【结束操作】
1
void forEach(Consumer<? super T> action);
该方法接受一个Consumer接口, 会将每一个流元素交给函数处理
public class StreamTest05ForEach {
public static void main(String[] args) {
List<String> list = Arrays.asList("xiaoming", "peiqi", "zhangsan");
Stream<String> stream = list.stream();
stream.forEach((s) -> { //forEach是一个结束操作
System.out.println(s);
});
list.stream().forEach(System.out::println);
}
}
4.2 count
count 方法用来统计Stream流中元素的个数【结束操作】
long count();
public class StreamTest06Count {
public static void main(String[] args) {
long count = Stream.of("tom", "java", "mybatis", "marry").count(); //count也是一个结束操作
System.out.println("count = " + count); //count = 4
}
}
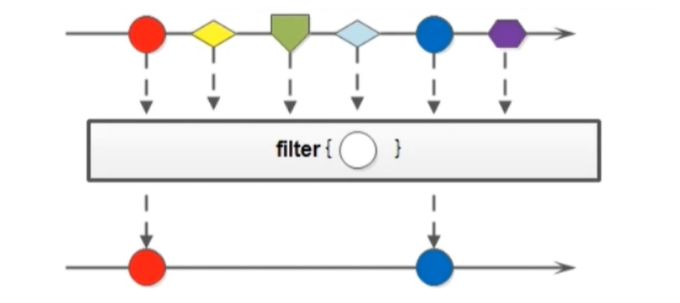
4.3 filter
filter 方法的作用是用来过滤数据的, 返回符合条件的数据流 (中间操作)
Stream<T> filter(Predicate<? super T> predicate); //在使用filter的时候使用的需要接受一个 Predicate 函数式接口参数
public static void main(String[] args) {
Stream.of("A1", "a1", "a2", "b3", "f4", "a3", "l5")
.filter((s) -> s.contains("a"))
.forEach(System.out::println);
}
输出:
a1
a2
a3
4.4 limit
limit方法可以对流进行截取,只取前n个数据, (中间操作),返回的是一个新的流对象
Stream<T> limit(long maxSize);
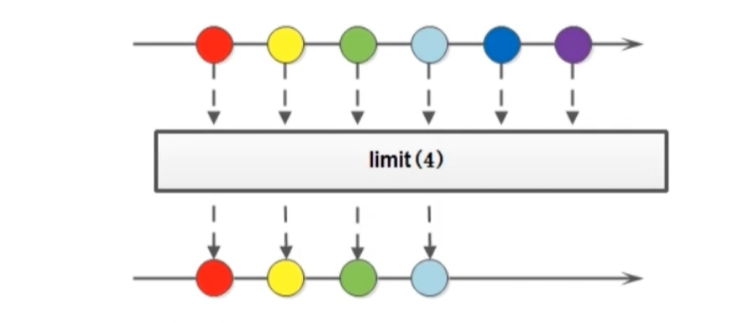
public static void main(String[] args) {
Stream.of("A1", "a1", "a2", "b3", "f4", "a3", "l5")
.limit(4) //只截取前面4个数字
.forEach(System.out::println);
}
输出:
A1
a1
a2
b3
4.5 skip
skip方法的作用是跳过前面的n个元素(中间操作), 返回的是一个新的流对象, 作用是和limit是相反的
Stream<T> skip(long n);
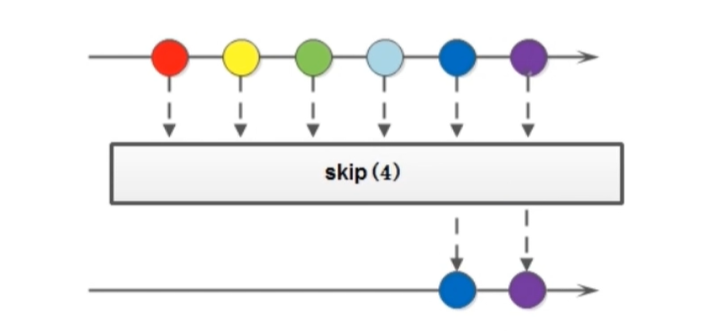
public static void main(String[] args) {
Stream.of("A1", "a1", "a2", "b3", "f4", "a3", "l5")
.skip(4) //跳过前面4个数字
.forEach(System.out::println);
}
输出:
f4
a3
l5
4.6 map
如果我们需要将流中的元素映射到另一个流中,可以使用map方法, 使用得时候需要传入Function函数式接口参数
<R> Stream<R> map(Function<? super T, ? extends R> mapper);
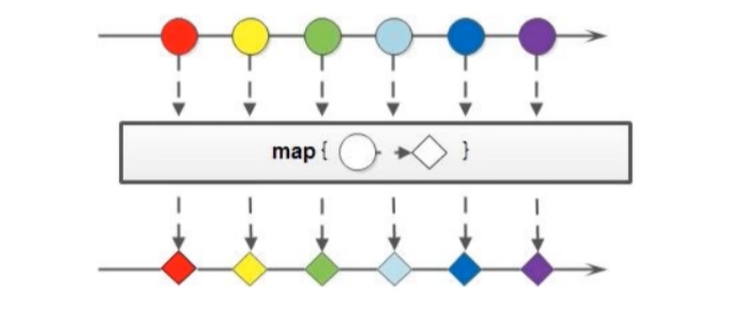
public static void main(String[] args) {
Stream.of("1", "9", "7", "4", "2", "6")
.map(s -> Integer.parseInt(s) + 100) //将传入的字符串类型转换为int型再加上100
.forEach(System.out::println);
}
输出:
101
109
107
104
102
106
4.7 sorted
sorted方法可以将流中的数据进行排序, (中间操作) 这个方法存在一个重载函数
Stream<T> sorted(); //sorted排序函数: 无需传入参数
Stream<T> sorted(Comparator<? super T> comparator); //重载的sorted排序函数: 需要传入Comparator的函数式接口
public static void main(String[] args) {
Stream.of("1", "9", "7", "4", "2", "6")
.map(s -> Integer.parseInt(s) + 100) //将传入的字符串类型转换为int型再加上100
.sorted() //进行默认排序, 递增
.forEach(System.out::println);
}
public static void main(String[] args) {
Stream.of("1", "9", "7", "4", "2", "6")
.map(s -> Integer.parseInt(s) + 100) //将传入的字符串类型转换为int型再加上100
// .sorted()
.sorted((a1, a2) -> a2 - a1) //传入一个Comparator的函数式接口,可以自定义排序规则
.forEach(System.out::println);
}
### 4.8 distinct
distinct方法的作用是去掉重复数据, 但是需要注意的是什么情况下才算重复(通过重写equals()和hashcode()方法) 返回一个新的Stream流(中间操作)
注意: Stream类中的 distinct 方法对于基本数据类型是可以直接去重的, 但是对于自定义类型的数据, 需要手动重写hashcode和equals方法来移除重复元素
1
Stream<T> distinct();
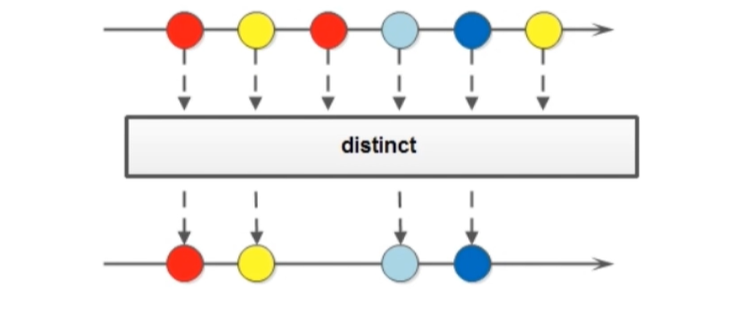
1
2
3
4
5
6
7
8
public static void main(String[] args) {
Stream.of("1", "9", "7", "4", "2", "6","2") //重复的2
.map(s -> Integer.parseInt(s) + 100) //将传入的字符串类型转换为int型再加上100
// .sorted()
.sorted((a1, a2) -> a2 - a1) //传入一个Comparator的函数式接口,可以自定义排序规则
.distinct() //去重
.forEach(System.out::println);
}
输出:
109
107
106
104
102 //只有一个102
101
注意: distinct方法对自定义的数据类型去重, 一定要重写 equals 方法和 hashcode 方法, 否则去重结果可能不符合预想结果
public static void main(String[] args) {
ArrayList<Person> people = new ArrayList<>();
people.add(new Person("张三", 19));
people.add(new Person("李四", 19));
people.add(new Person("张三", 19));
people.add(new Person("小明", 23));
people.add(new Person("张三", 19, 175.0));
people.stream()
.distinct() //自定义类型没有重写equals和hashcode方法时可能不是自己想要的去重
.forEach(System.out::println);
}
输出结果: 去重效果不理想
Person{name='张三', age=19, height=null}
Person{name='李四', age=19, height=null}
Person{name='张三', age=19, height=null}
Person{name='小明', age=23, height=null}
Person{name='张三', age=19, height=175.0}
只根据name和age 重写Person的equals和hashcode方法
@Override
public boolean equals(Object o) {
if (this == o) {
return true;
}
if (o == null || getClass() != o.getClass()) {
return false;
}
Person person = (Person) o;
return Objects.equals(name, person.name) && Objects.equals(age, person.age);
}
@Override
public int hashCode() {
return Objects.hash(name, age);
}
再次执行之前的distinct方法
public static void main(String[] args) {
ArrayList<Person> people = new ArrayList<>();
people.add(new Person("张三", 19));
people.add(new Person("李四", 19));
people.add(new Person("张三", 19));
people.add(new Person("小明", 23));
people.add(new Person("张三", 19, 175.0));
people.stream()
.distinct() //自定义类型重写了equals和hashcode方法
.forEach(System.out::println);
}
输出结果: 只用根据person的name和age去重
Person{name='张三', age=19, height=null}
Person{name='李四', age=19, height=null}
Person{name='小明', age=23, height=null}
** 和 equals 和 hashcode 详解**: https://www.cnblogs.com/kexianting/p/8508207.html#:~:text=Java%E5%AF%B9%E4%BA%8Eeqauls%E6%96%B9%E6%B3%95%E5%92%8ChashCode%E6%96%B9%E6%B3%95%E6%98%AF%E8%BF%99%E6%A0%B7%E8%A7%84%E5%AE%9A%E7%9A%84%EF%BC%9A%20%281%29%E5%90%8C%E4%B8%80%E5%AF%B9%E8%B1%A1%E4%B8%8A%E5%A4%9A%E6%AC%A1%E8%B0%83%E7%94%A8hashCode%28%29%E6%96%B9%E6%B3%95%EF%BC%8C%E6%80%BB%E6%98%AF%E8%BF%94%E5%9B%9E%E7%9B%B8%E5%90%8C%E7%9A%84%E6%95%B4%E5%9E%8B%E5%80%BC%E3%80%82,%282%29%E5%A6%82%E6%9E%9Ca.equals%28b%29%EF%BC%8C%E5%88%99%E4%B8%80%E5%AE%9A%E6%9C%89a.hashCode%28%29%20%E4%B8%80%E5%AE%9A%E7%AD%89%E4%BA%8E%20b.hashCode%28%29%E3%80%82
4.9 match
如果需要判断数据是否满足指定的条件, 则可以使用match的相关方法, 【终结操作】
boolean anyMatch(Predicate<? super T> predicate); //是否任意一个元素满足条件 anyMatch
boolean allMatch(Predicate<? super T> predicate); //是否所有元素都要满足条件 allMatch
boolean noneMatch(Predicate<? super T> predicate); //是否所有元素都不满足条件 noneMatch
使用:
Stream<String> stringStream = Stream.of("1", "9", "7", "4", "2", "6");
boolean match = stringStream
//.map(s -> Integer.parseInt(s))
.map(Integer::parseInt)
.anyMatch(i -> i > 5); //任意一个元素大于5
System.out.println("match = " + match);
}
输出:
match = true
public static void main(String[] args) {
Stream<String> stringStream = Stream.of("1", "9", "7", "4", "2", "6");
boolean match = stringStream
.map(Integer::parseInt)
.allMatch(integer -> integer > 5); //所有元素大于5
System.out.println("match = " + match);
}
输出:
match = false
public static void main(String[] args) {
Stream<String> stringStream = Stream.of("1", "9", "7", "4", "2", "6");
boolean match = stringStream
.map(Integer::parseInt)
.noneMatch(integer -> integer > 10); //所有元素都不大于10
System.out.println("match = " + match);
}
输出:
match = true
4.10 find
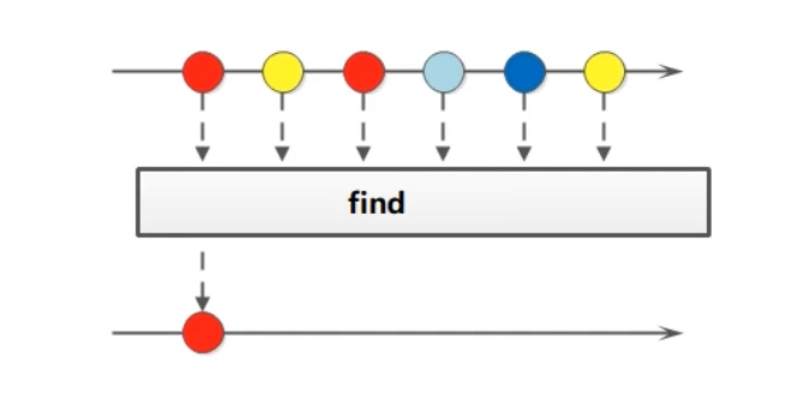
查找流中的元素可以使用find 的相应方法, findAny()方法返回Stream中的任何元素的Optional,而findFirst()方法返回Stream中的第一个元素的Optional 【终结操作】
https://blog.csdn.net/weixin_39132705/article/details/107338638
1
2
Optional<T> findFirst(); //返回Stream中的第一个元素
Optional<T> findAny(); //返回Stream中的任何元素, 很可能返回Stream中的第一个元素,但不保证这一点
1
2
3
4
5
6
7
8
9
10
11
public static void main(String[] args) {
Optional<String> first = Stream.of("10", "9", "7", "4", "2", "6").findFirst();
System.out.println("first.get() = " + first.get());
Optional<String> any = Stream.of("10", "9", "7", "4", "2", "6").findAny();
System.out.println("any.get() = " + any.get());
}
输出:
first.get() = 10
any.get() = 10
4.11 max和min
max 和 min 返回流中元素最大值和最小值的Optional 【终结操作】
Optional<T> max(Comparator<? super T> comparator); //获取最大值
Optional<T> min(Comparator<? super T> comparator); //获取最小值
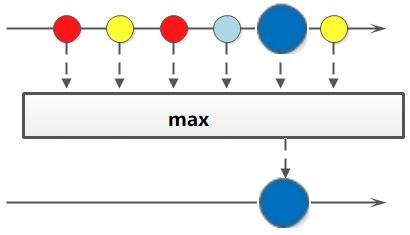
public static void main(String[] args) {
Optional<Integer> max = Stream.of("10", "90", "7", "4", "2", "6")
.map(Integer::parseInt)
.max((o1, o2) -> o1 - o2); //需要传入一个Comparator, 可以自定义规则
System.out.println("max.get() = " + max.get());
Optional<Integer> min = Stream.of("10", "90", "7", "4", "2", "6")
.map(Integer::parseInt)
.max((o1, o2) -> o2 - o1); //需要传入一个Comparator, 可以自定义规则
System.out.println("min.get() = " + min.get());
}
输出:
max.get() = 90
min.get() = 2
4.12 *reduce
归约,也称缩减,顾名思义,是把一个流缩减成一个值,能实现对集合求和、求乘积和求最值操作。【终结操作】
将流中的所有数据进行归纳得到一个数据, 可以使用reduce方法
reduce操作可以实现从一组元素中生成一个值,sum()、max()、min()、count()等都是reduce操作,将他们单独设为函数只是因为常用。2
<U> U reduce(U identity,
BiFunction<U, ? super T, U> accumulator,
BinaryOperator<U> combiner);
------------------------------------------------------------------------------------------
Optional<T> reduce(BinaryOperator<T> accumulator);
------------------------------------------------------------------------------------------
T reduce(T identity, BinaryOperator<T> accumulator); //主要使用的是这一个方法

public static void main(String[] args) {
Integer sum = Stream.of(1, 2, 3, 4, 5)
//identity是默认值
//第一次的时候会将默认值给x
//之后的每一次操作会将上一次操作的结果赋值给x, y就只是从数据中获取元素
.reduce(0, (x, y) -> {
System.out.println("x = " + x + " y = " + y);
return x + y; //求和操作
});
System.out.println("sum = " + sum);
}
输出:
x = 0 y = 1
x = 1 y = 2
x = 3 y = 3
x = 6 y = 4
x = 10 y = 5
sum = 15
Integer max = Stream.of(1, 2, 3, 4, 50, 3, 1)
.reduce(0, (x, y) -> {
return x > y ? x : y; //获取最大值
});
System.out.println("max = " + max);
输出:
max = 50
4.13 map和reduce组合
在实际开发中经常会让map和reduce一块使用
public static void main(String[] args) {
ArrayList<Person> people = new ArrayList<>();
people.add(new Person("小明", 19));
people.add(new Person("小明亮", 18));
people.add(new Person("小红", 16));
people.add(new Person("汤姆", 26));
people.add(new Person("佩奇", 20));
//求出所有人员的年龄中和
Integer maxAge = people.stream()
// .map(p -> p.getAge())
.map(Person::getAge) //map对数据类型进行转换
.reduce(0, (x, y) -> x > y ? x : y); //reduce对数据进行归约
System.out.println("maxAge = " + maxAge);
//求出所有人员的年龄总和
Integer sumAge = people.stream()
.map(Person::getAge)
.reduce(0, Integer::sum);
System.out.println("sumAge = " + sumAge);
//获取"a"出现的次数
Integer count = Stream.of("a", "c", "v", "s", "a", "a")
.map(s -> "a".equals(s) ? 1 : 0)
.reduce(0, Integer::sum);
System.out.println("count = " + count);
}
输出:
maxAge = 26
sumAge = 99
count = 3
4.14 mapToInt …
mapToInt的作用: 可以先将流中的Integer数据转换为int数据 (中间操作)
Integer占用的内存比int多很多, 在Stream流操作中会频繁的自动拆箱和装箱, 很浪费空间
IntStream mapToInt(ToIntFunction<? super T> mapper); //转换为基本数据类型int
LongStream mapToLong(ToLongFunction<? super T> mapper); //转换为基本数据类型long
DoubleStream mapToDouble(ToDoubleFunction<? super T> mapper);//转换为基本数据类型double
public static void main(String[] args) {
Integer[] array = {10, 20, 30, 40, 50, 60};
//Integer占用的内存比int多很多, 在Stream流操作中会频繁的自动拆箱和装箱, 很浪费空间
Stream.of(array)
.filter(item -> item > 20)
.forEach(System.out::println);
System.out.println("=================");
//为了提高代码的效率,可以先将流中的Integer数据转换为int数据,然后在操作数据
Stream.of(array)
.mapToInt(Integer::intValue) //先将Integer数据转换为int数据
.filter(i -> i > 20)
.forEach(System.out::println);
}
输出:
30
40
50
60
=================
30
40
50
60
4.15 concat
concat可以将两个流合并成为一个流, 可以使用Stream类的静态方法concat (中间操作)
public static <T> Stream<T> concat(Stream<? extends T> a, Stream<? extends T> b) {
Objects.requireNonNull(a);
Objects.requireNonNull(b);
@SuppressWarnings("unchecked")
Spliterator<T> split = new Streams.ConcatSpliterator.OfRef<>(
(Spliterator<T>) a.spliterator(), (Spliterator<T>) b.spliterator());
Stream<T> stream = StreamSupport.stream(split, a.isParallel() || b.isParallel());
return stream.onClose(Streams.composedClose(a, b));
}
public static void main(String[] args) {
Integer[] array = {10, 20, 30, 40, 50, 60};
ArrayList<Integer> doubles = new ArrayList<>();
doubles.add(12);
doubles.add(12);
doubles.add(12);
Stream<Integer> stream1 = Stream.of(array);
Stream<Integer> stream2 = doubles.stream();
Stream<Integer> concat = Stream.concat(stream1, stream2); //合并两个流
concat
.mapToInt(Integer::intValue)
.sorted()
.filter(i -> i > 40)
.forEach(System.out::println);
}
输出:
50
60
5.Stream数据收集collect
5.1将结果收集到数组中
Stream中提供了toArray方法将Stream流中的数据放到数组中, 返回类型是Object[]数组, 如果需要自定义返回数组类型需要传入相应类型的构造器参数
//1.使用无参,收集到数组,返回值为 Object[](Object类型将不好操作)
Object[] toArray();
//2.使用有参,可以指定将数据收集到指定类型数组,方便后续对数组的操作
<A> A[] toArray(IntFunction<A[]> generator);
public static void main(String[] args) {
ArrayList<Person> people = new ArrayList<>();
people.add(new Person("张三丰", 21));
people.add(new Person("李四", 20));
people.add(new Person("王五", 17));
people.add(new Person("麦克", 16));
//将stream流转化为数组, toArray()没有指定类型直接转为Object
Object[] objects = people.stream().toArray();
for (Object o : objects) {
if (o instanceof Person) {
Person person = (Person) o;
System.out.println("person.getName() = " + person.getName());
}
}
//将stream流转化为指定类型的数组,
Person[] people1 = people.stream().toArray(Person[]::new);
for (Person person : people1) {
System.out.println(person);
}
}
输出:
person.getName() = 张三丰
person.getName() = 李四
person.getName() = 王五
person.getName() = 麦克
Person{name='张三丰', age=21, height=null}
Person{name='李四', age=20, height=null}
Person{name='王五', age=17, height=null}
Person{name='麦克', age=16, height=null}
5.2将结果收集到集合中
Stream的终极武器: 将Stream转换成容器或Map (终结操作) https://www.cnblogs.com/CarpenterLee/p/6550212.htm
<R, A> R collect(Collector<? super T, A, R> collector);
<R> R collect(Supplier<R> supplier,
BiConsumer<R, ? super T> accumulator,
BiConsumer<R, R> combiner);
收集器(Collector)是为Stream.collect()方法量身打造的工具接口(类)。考虑一下将一个Stream转换成一个Collection集合(或者Map)需要做哪些工作?我们至少需要三样东西:
- 目标容器是什么?是ArrayList还是HashSet,或者是个TreeMap。
- 新元素如何添加到容器中?是
List.add()还是Map.put()。 - 如果并行的进行规约,还需要告诉collect() 多个部分结果如何合并成一个。
-
结合以上分析,collect()方法定义为
<R> R collect(Supplier<R> supplier, //目标容器是什么 BiConsumer<R, ? super T> accumulator, //如何添加新元素 BiConsumer<R, R> combiner); //并行规约, 如何合并三个参数依次对应上述三条分析
-
不过每次调用collect()都要传入这三个参数太麻烦,收集器Collector就是对这三个参数的简单封装,所以collect()的另一定义为
<R, A> R collect(Collector<? super T, A, R> collector);Collectors工具类可通过静态方法生成各种常用的Collector。举例来说,如果要将Stream规约成List可以通过如下两种方式实现:
// 将Stream规约成List Stream<String> stream = Stream.of("I", "love", "you", "too"); List<String> list = stream.collect(ArrayList::new, ArrayList::add, ArrayList::addAll);// 方式1 //List<String> list = stream.collect(Collectors.toList());// 方式 2 System.out.println(list);
通常情况下我们不需要手动指定collect()的三个参数,而是调用collect(Collector<? super T,A,R> collector)方法,并且参数中的Collector对象大都是直接通过Collectors工具类获得。实际上传入的收集器的行为决定了collect()的行为。
5.2.1 使用collect()生成Collection
将Stream转换成List或Set是比较常见的操作,所以Collectors工具已经为我们提供了对应的收集器,通过如下代码即可完成:
public static void main(String[] args) {
Stream<String> stream1 = Stream.of("I", "love", "you", "too");
List<String> list = stream1.collect(Collectors.toList()); //将stream流转化为list集合
Stream<String> stream2 = Stream.of("I", "love", "you", "too");
Set<String> set = stream2.collect(Collectors.toSet()); //将stream流转化为set集合
}
上述代码能够满足大部分需求,但由于返回结果是接口类型,我们并不知道类库实际选择的容器类型是什么,有时候我们可能会想要人为指定容器的实际类型,这个需求可通过Collectors.toCollection(Supplier<C> collectionFactory)方法完成。
public static void main(String[] args) {
Stream<String> stream1 = Stream.of("I", "love", "you", "too");
// 通过Collectors.toCollection(Supplier<C> collectionFactory)转化为集合
ArrayList<String> arrayList = stream1.collect(Collectors.toCollection(ArrayList::new)); //转化为ArrayList
Stream<String> stream2 = Stream.of("I", "love", "you", "too");
HashSet<String> hashSet = stream2.collect(Collectors.toCollection(HashSet::new)); //转化为HashSet
}
基本上述的两种方式足够应对collect()方法转Collection集合
public static void main(String[] args) {
Stream<String> stream = Stream.of("I", "love", "you", "too"); ///注意Stream只能用一次, 下面代码编译不通过, 只是方便记笔记
List<String> list = stream.collect(Collectors.toList()); //将stream流转化为list集合
ArrayList<Object> arrayList1 = stream.collect(ArrayList::new, ArrayList::add, ArrayList::addAll); //方式2
Set<String> set = stream.collect(Collectors.toSet()); //将stream流转化为set集合
HashSet<Object> hashSet1 = stream.collect(HashSet::new, HashSet::add, HashSet::addAll); //方式2
// 通过Collectors.toCollection(Supplier<C> collectionFactory)转化为集合
ArrayList<String> arrayList = stream.collect(Collectors.toCollection(ArrayList::new)); //转化为ArrayList
HashSet<String> hashSet = stream.collect(Collectors.toCollection(HashSet::new)); //转化为HashSet
}
除了 collect() 方法将数据收集到集合/数组中。对 Stream流 的收集还有其他的方法。比如说:聚合计算,分组,多级分组,分区,拼接等。
5.2.2 使用collect()生成Map
Stream背后依赖于某种数据源,数据源可以是数组、容器等,但不能是Map。反过来从Stream生成Map是可以的,但我们要想清楚Map的key和value分别代表什么,根本原因是我们要想清楚要干什么。通常在三种情况下collect()的结果会是Map:
- 使用
Collectors.toMap()生成的收集器,用户需要指定如何生成Map的key和value。 - 使用
Collectors.partitioningBy()生成的收集器,对元素进行二分区操作时用到。 - 使用
Collectors.groupingBy()生成的收集器,对元素做group操作时用到。
- 第一种情况:Collectors.toMap() 需要指定如何生成Map的key和value
public static void main(String[] args) {
ArrayList<Person> people = new ArrayList<>();
people.add(new Person("张三", 19));
people.add(new Person("李四", 20));
people.add(new Person("王五", 18));
people.add(new Person("麦克", 16));
//将stream流转化为map集合
Map<Person, String> map = people.stream()
.collect(Collectors.toMap(Function.identity(), //如何生成key
Person::getName)); //如何生成value
Set<Person> keySet = map.keySet();
for (Person person : keySet) {
System.out.println(person);
}
Collection<String> values = map.values();
for (String value : values) {
System.out.println(value);
}
}
提示: Function.identity()返回一个 输出 跟 输入 一样的Lambda表达式对象,等价于形如t -> t形式的Lambda表达式。
输出:
Person{name='麦克', age=16, height=null}
Person{name='王五', age=18, height=null}
Person{name='张三', age=19, height=null}
Person{name='李四', age=20, height=null}
麦克
王五
张三
李四
- 第二种情况: 使用
partitioningBy()生成的收集器,这种情况适用于将Stream中的元素依据某个二值逻辑(满足条件,或不满足)分成互补相交的两部分,比如男女性别、成绩及格与否等。下列代码展示将人员分为成年和未成年。
public static void main(String[] args) {
ArrayList<Person> people = new ArrayList<>();
people.add(new Person("张三", 21));
people.add(new Person("李四", 20));
people.add(new Person("王五", 17));
people.add(new Person("麦克", 16));
//将人员分为成年和未成年两部分
Map<Boolean, List<Person>> listMap = people.stream()
.collect(Collectors.partitioningBy(person -> person.getAge() >= 18));
System.out.println(listMap);
}
输出:
{false=[Person{name='王五', age=17, height=null}, Person{name='麦克', age=16, height=null}],
true=[Person{name='张三', age=21, height=null}, Person{name='李四', age=20, height=null}]}
- 第三种情况:使用
groupingBy()生成的收集器,这是比较灵活的一种情况。跟SQL中的group by语句类似,这里的groupingBy()也是按照某个属性对数据进行分组,属性相同的元素会被对应到Map的同一个key上。下列代码展示将员工按照部门进行分组:
// Group employees by department
Map<Department, List<Employee>> byDept = employees.stream()
.collect(Collectors.groupingBy(Employee::getDepartment));
5.2.3 Collectors的聚合计算
当我们使用stream流处理数据后, 可以像数据库的聚合函数一样对某个字段进行操作, 比如获取最大值,最小值, 平均值, 求和, 统计计数等操作
public class StreamTest23polymerize {
public static void main(String[] args) {
HashSet<Student> students = new HashSet<>();
students.add(new Student("zhangsan", 18, 82));
students.add(new Student("lisi", 16, 92));
students.add(new Student("jack", 20, 62));
students.add(new Student("marry", 28, 59));
students.add(new Student("tom", 26, 80));
Optional<Student> maxAgePerson = students.stream()
.map((student) -> {
student.setScore(student.getScore() + 1); //每人的成绩加1
return student;
})
.collect(Collectors.maxBy((x, y) -> x.getAge() - y.getAge()));
System.out.println("年龄最大的Person = " + maxAgePerson.get());
Optional<Student> minAgePerson = students.stream()
.map((student) -> {
student.setScore(student.getScore() + 1); //每人的成绩加一
return student;
})
.collect(Collectors.minBy((x, y) -> x.getAge() - y.getAge()));
System.out.println("年龄最小的Person = " + minAgePerson.get());
Integer ageSum = students.stream()
.collect(Collectors.summingInt(s -> s.getAge()));
System.out.println("年龄之和为: " + ageSum);
Double average = students.stream()
.collect(Collectors.averagingInt(Student::getScore));
System.out.println("平均成绩: " + average);
Long count = students.stream()
.collect(Collectors.counting());
System.out.println("Person人数: " + count);
}
}
输出:
年龄最大的Person = Student(name=marry, age=28, score=60)
年龄最小的Person = Student(name=lisi, age=16, score=94)
年龄之和为: 108
平均成绩: 77.0
Person人数: 5
5.2.4 Collectors的分组操作
当我们使用stream流处理数据后, 可以像数据库的聚合函数一样对某个字段进行分组, 可以根据一个字段分组也可以根据多个字段分组
- 根据一个属性分组
public class StreamTest24group {
public static void main(String[] args) {
HashSet<Student> students = new HashSet<>();
students.add(new Student("zhangsan", 18, 48));
students.add(new Student("lisi", 16, 92));
students.add(new Student("jack", 21, 62));
students.add(new Student("marry", 17, 59));
students.add(new Student("tom", 26, 82));
Map<String, List<Student>> map = students.stream()
.collect(Collectors.groupingBy(s -> s.getAge() >= 18 ? "成年" : "未成年"));
map.forEach((k, v) -> System.out.println("K=" + k + " v=" + v));
Map<String, List<Student>> map1 = students.stream()
.collect(Collectors.groupingBy(student -> student.getScore() >= 60 ? "成绩合格" : "成绩不合格"));
map1.forEach((k, v) -> System.out.println("K=" + k + " v=" + v));
}
}
输出:
K=未成年 v=[Student(name=marry, age=17, score=59), Student(name=lisi, age=16, score=92)]
K=成年 v=[Student(name=tom, age=26, score=82), Student(name=jack, age=21, score=62), Student(name=zhangsan, age=18, score=48)]
============
K=成绩合格 v=[Student(name=tom, age=26, score=82), Student(name=jack, age=21, score=62), Student(name=lisi, age=16, score=92)]
K=成绩不合格 v=[Student(name=marry, age=17, score=59), Student(name=zhangsan, age=18, score=48)]
也可以实现多级分组:
System.out.println("==========多级分组==========");
Map<Integer, Map<String, List<Student>>> mapMap = students.stream()
.collect(Collectors.groupingBy(
Student::getAge,
Collectors.groupingBy(s -> s.getScore() >= 60 ? "及格" : "不及格")));
mapMap.forEach(
(k1, v1) -> {
System.out.println(k1);
v1.forEach(
(k2, v2) -> System.out.println(k2 + ": v2 = " + v2)
);
}
);
输出:
==========多级分组==========
16
及格: v2 = [Student(name=tom, age=16, score=82), Student(name=lisi, age=16, score=92), Student(name=jack, age=16, score=62)]
20
不及格: v2 = [Student(name=zhangsan, age=20, score=48), Student(name=marry, age=20, score=59)]
5.2.5 Collectors的分区操作
Collectors. partitioningBy会根据值是否为true把集合中的数据分割为两个列表,一个true列表,一个fase列表

public static void main(String[] args) {
ArrayList<Student> students = new ArrayList<>();
students.add(new Student("zhangsan", 20, 48));
students.add(new Student("lisi", 16, 92));
students.add(new Student("jack", 16, 62));
students.add(new Student("marry", 20, 59));
students.add(new Student("xiaoming", 16, 82));
Map<Boolean, List<Student>> map = students.stream()
.collect(Collectors.partitioningBy(student -> student.getAge() >= 18));
map.forEach((k, v) -> System.out.println("k = " + k + " v = " + v));
}
输出:
k = false v = [Student(name=lisi, age=16, score=92), Student(name=jack, age=16, score=62), Student(name=xiaoming, age=16, score=82)]
k = true v = [Student(name=zhangsan, age=20, score=48), Student(name=marry, age=20, score=59)]
5.2.6 Collectors的拼接操作
Collectors.joining会根据指定的连接符,将所有的元素连接成一个字符串
public static void main(String[] args) {
ArrayList<Student> students = new ArrayList<>();
students.add(new Student("zhangsan", 20, 48));
students.add(new Student("lisi", 16, 92));
students.add(new Student("jack", 16, 62));
students.add(new Student("marry", 20, 59));
students.add(new Student("xiaoming", 16, 82));
String all = students.stream()
.map(Student::getName)
.collect(Collectors.joining()); //直接拼接
System.out.println(all);
String all2 = students.stream()
.map(Student::getName)
.collect(Collectors.joining("_")); //使用 _ 作为分隔符拼接
System.out.println(all2);
String all3 = students.stream()
.map(Student::getName)
.collect(Collectors.joining("_", "***", "&&&")); //分隔符, 前缀, 后缀
System.out.println(all3);
}
输出:
zhangsanlisijackmarryxiaoming
zhangsan_lisi_jack_marry_xiaoming
***zhangsan_lisi_jack_marry_xiaoming&&&
更多collect()方法详情: https://www.cnblogs.com/CarpenterLee/p/6550212.html
6.并行流
parallelStream其实就是一个并行执行的流.它通过默认的ForkJoinPool,可能提高你的多线程任务的速度.
并行流就是将一个流的内容分成多个数据块,并用不同的线程分别处理每个不同数据块的流
https://blog.csdn.net/u011001723/article/details/52794455?spm=1001.2101.3001.6650.3&utm_medium=distribute.pc_relevant.none-task-blog-2%7Edefault%7ECTRLIST%7ERate-3.pc_relevant_paycolumn_v3&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2%7Edefault%7ECTRLIST%7ERate-3.pc_relevant_paycolumn_v3&utm_relevant_index=4
public static void main(String[] args) {
System.out.println("串行的stream流");
Stream.of(10, 20, 3, 40, 5, 6)
.forEach(item -> {
System.out.println("Thread id = " + Thread.currentThread().getName() + " v = " + item);
});
System.out.println("================");
System.out.println("并行的stream流");
Stream.of(10, 20, 3, 40, 5, 6)
.parallel() //转化为并行流
.forEach(item -> {
System.out.println("Thread id = " + Thread.currentThread().getName() + " v = " + item);
});
}
输出:
串行的stream流
Thread id = main v = 10
Thread id = main v = 20
Thread id = main v = 3
Thread id = main v = 40
Thread id = main v = 5
Thread id = main v = 6
================
并行的stream流
Thread id = main v = 40
Thread id = main v = 6
Thread id = ForkJoinPool.commonPool-worker-2 v = 10
Thread id = main v = 5
Thread id = ForkJoinPool.commonPool-worker-2 v = 3
Thread id = ForkJoinPool.commonPool-worker-1 v = 20
6.1获取并行流的方式
我们可以通过两种方式来获取并行流
- 通过Collection接口中的 .parallelStream()方法获取并行流
- 将已有的串行流转化为并行流.parallel()方法
public static void main(String[] args) {
List<Integer> arrayList = new ArrayList<>();
//通过Collection接口中的 .parallelStream()方法获取并行流
Stream<Integer> parallelStream = arrayList.parallelStream();
//将已有的串行流转化为并行流.parallel()方法
Stream<Integer> parallel = Stream.of(1, 2, 3, 4, 5).parallel();
}
6.2串行流和并行流的区别
串行流是单线程的, 顺序执行, 线程是安全的
并行流式多线程的, 随机执行, 线程是不安全的, 但是可以通过一些手段解决线程安全问题
public static void main(String[] args) {
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9);
numbers.parallelStream()
.forEach(System.out::println); //随机输出
System.out.println("+++++++++++++++");
numbers.parallelStream()
.forEachOrdered(System.out::println);
}
输出:
6 //输出是无序随机的
5
8
9
3
4
2
1
7
+++++++++++++++
1 //输出是经过排序的
2
3
4
5
6
7
8
9
注意: 如果forEachOrdered()中间有其他如filter()的中介操作,会试着平行化处理,然后最终forEachOrdered()会以原数据顺序处理,因此,使用forEachOrdered()这类的有序处理,可能会(或完全失去)失去平行化的一些优势,实际上中介操作亦有可能如此,例如sorted()方法。
6.3并行流的线程安全问题
在多线程的处理下, 肯定会出现数据安全的问题.
public static void main(String[] args) {
ArrayList<Integer> list = new ArrayList<>();
for (int i = 0; i < 1000; i++) {
list.add(i);
}
System.out.println(list.size());
//将list中的数据转移到另一个list中,
ArrayList<Integer> newList = new ArrayList<>();
list.parallelStream() //这种情况下使用并行流, 会出现线程安全问题
.forEach(newList::add);
System.out.println(newList.size());
}
输出: 已经出现线程安全问题, 编译器并没有报错
1
2
1000
932 //数量没有1000,已经出现线程安全问题
线程安全问题的解决方案
-
使用同步代码块:
public static void main(String[] args) { ArrayList<Integer> list = new ArrayList<>(); for (int i = 0; i < 1000; i++) { list.add(i); } System.out.println(list.size()); //将list中的数据转移到另一个list中, ArrayList<Integer> newList = new ArrayList<>(); Object obj = new Object(); list.parallelStream() //添加同步代码块 .forEach(item -> { synchronized (obj) { //添加同步代码块实现线程安全 newList.add(item); } }); System.out.println(newList.size()); }输出: 使用同步代码块后就不会再出现数据安全问题
1000 1000 -
使用线程安全的容器
public static void main(String[] args) { Vector<Integer> newList = new Vector<>(); //Vector是线程安全的容器 IntStream.rangeClosed(1, 1000).parallel() // .forEach(newList::add); .forEach(item -> { newList.add(item); }); System.out.println(newList.size()); }输出:
1000 -
将线程不安全的容器转化为线程安全的容器
public static void main(String[] args) { ArrayList<Integer> list = new ArrayList<>(); //arrayList是线程不安全的容器 //将线程不安全的arrayList转化为线程安全的 List<Integer> synchronizedList = Collections.synchronizedList(list); IntStream.rangeClosed(1, 1000).parallel() .forEach(synchronizedList::add); System.out.println(synchronizedList.size()); }输出:
1000 -
使用的stream的Collectors工具类提供的方法: 里面的方法满足线程安全问题
public static void main(String[] args) { ArrayList<Integer> list = new ArrayList<>(); //arrayList是线程不安全的容器 List<Integer> collect = IntStream.rangeClosed(1, 1000).parallel() .boxed() .collect(Collectors.toList()); System.out.println(collect.size()); // 注意: IntStream是存的是int类型的stream,而Steam是一个存了Integer的stream。 // boxed的作用就是将int类型的stream转成了Integer类型的Stream。 }输出:
1000
6.4并行流原理:ForkJoin框架
ForkJoin框架的目的是以递归的方式将可以并行的任务拆分成更小的任务,然后将每个子任务的结果合并起来生成整体结果.
它是 ExecutorService 接口的一个实现,他把子任务分配给线程池(ForkJoinPool)中的线程.
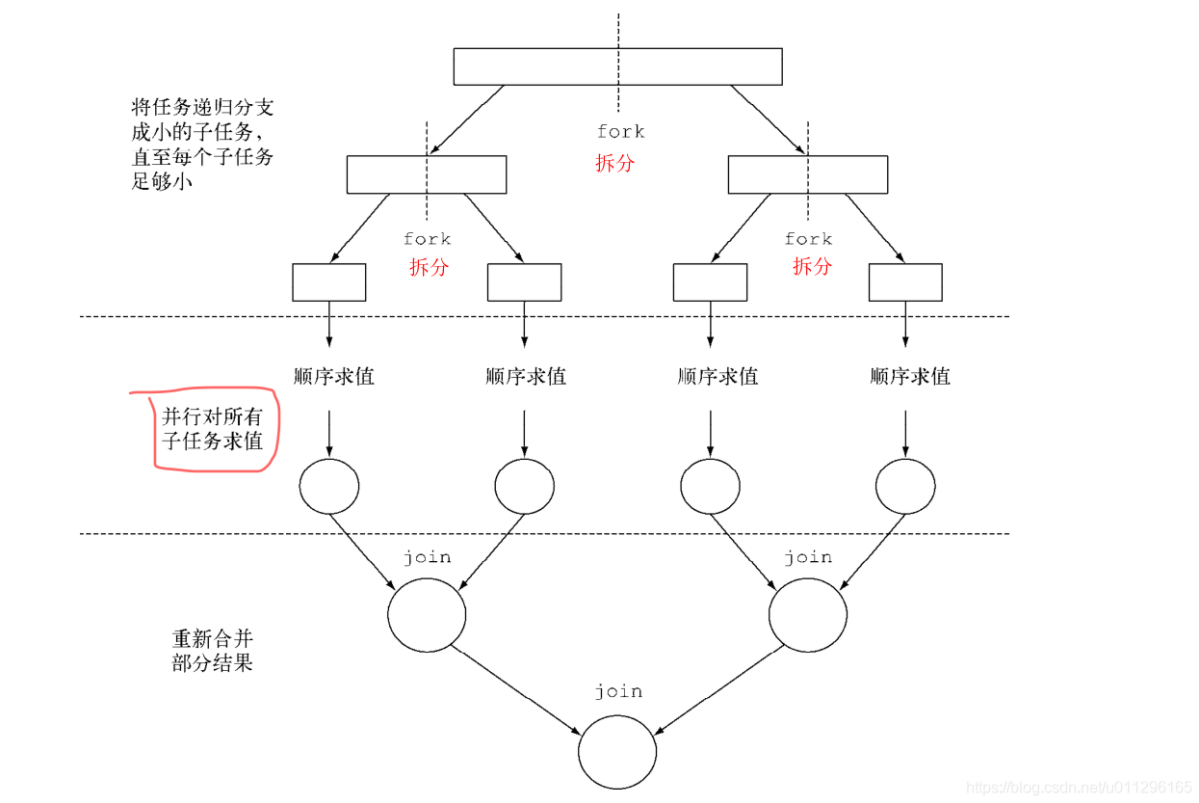
如果你了解著名的分治算法,会发现这不过是分支算法的并行版本而已
Fork/Join框架主要包含三个模块:
- 线程池: ForkJoinPool
- 任务对象: ForkJoinTask
- 执行任务的线程: ForkJoinWorkerThread
6.4.1 Fork/Join原理-分治法
ForkJoin框架是从jdk7中新特性,它同ThreadPoolExecutor一样,也实现了Executor和ExecutorService接口。它使用了一个无限队列来保存需要执行的任务,而线程的数量则是通过构造函数传入,如果没有向构造函数中传入希望的线程数量,那么当前计算机可用的CPU数量会被设置为线程数量作为默认值。
ForkJoinPool主要用来使用分治法(Divide-and-Conquer Algorithm)来解决问题。典型的应用比如快速排序算法。这里的要点在于,ForkJoinPool需要使用相对少的线程来处理大量的任务。比如要对1000万个数据进行排序,那么会将这个任务分割成两个500万的排序任务和一个针对这两组500万数据的合并任务。以此类推,对于500万的数据也会做出同样的分割处理,到最后会设置一个阈值来规定当数据规模到多少时,停止这样的分割处理。比如,当元素的数量小于10时,会停止分割,转而使用插入排序对它们进行排序。那么到最后,所有的任务加起来会有大概2000000+个。问题的关键在于,对于一个任务而言,只有当它所有的子任务完成之后,它才能够被执行。
所以当使用ThreadPoolExecutor时,使用分治法会存在问题,因为ThreadPoolExecutor中的线程无法像任务队列中再添加一个任务并且在等待该任务完成之后再继续执行。而使用ForkJoinPool时,就能够让其中的线程创建新的任务,并挂起当前的任务,此时线程就能够从队列中选择子任务执行。
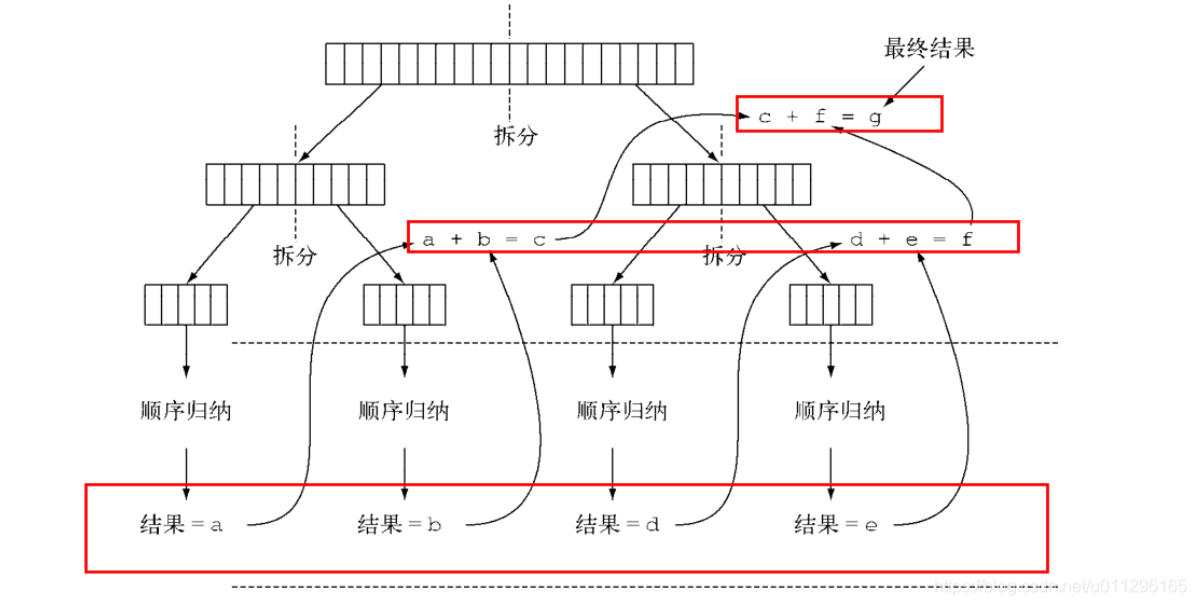
6.4.2 Fork/Join原理-工作窃取算法
forkjoin最核心的地方就是利用了现代硬件设备多核,在一个操作时候会有空闲的cpu,那么如何利用好这个空闲的cpu就成了提高性能的关键,而这里我们要提到的工作窃取(work-stealing)算法就是整个forkjion框架的核心理念,工作窃取(work-stealing)算法是指某个线程从其他队列里窃取任务来执行。
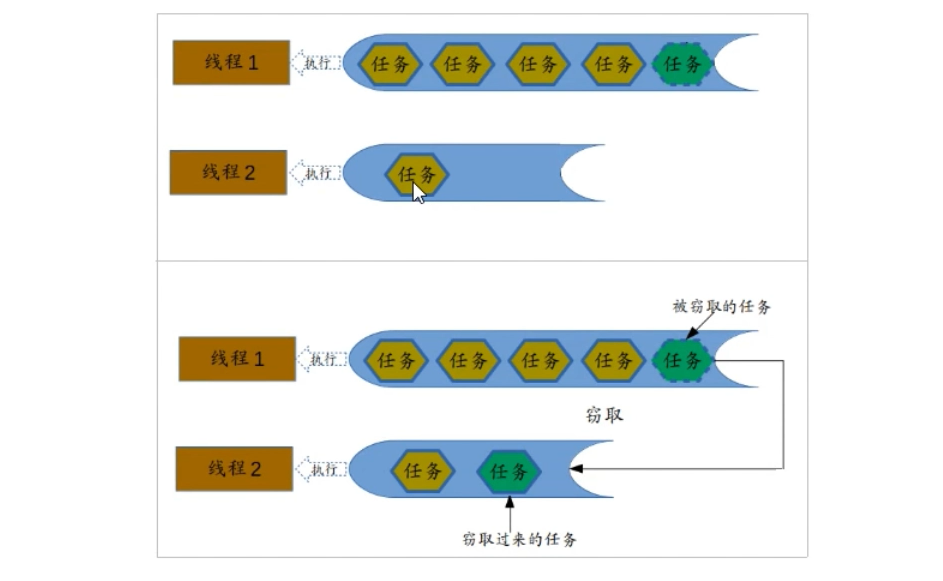
那么为什么需要使用工作窃取算法呢? 假如我们需要做一个比较大的任务,我们可以把这个任务分割为若干互不依赖的子任务,为了减少线程间的竞争,于是把这些子任务分别放到不同的队列里,并为每个队列创建一个单独的线程来执行队列里的任务,线程和队列一一对应,比如A线程负责处理A队列里的任务。 但是有的线程会先把自己队列里的任务干完,而其他线程对应的队列里还有任务等待处理。干完活的线程与其等着,不如去帮其他线程干活,于是它就去其他线程的队列里窃取一个任务来执行。而在这时它们会访问同一个队列,所以为了减少窃取任务线程和被窃取任务线程之间的竞争,通常会使用双端队列,被窃取任务线程永远从双端队列的头部拿任务执行,而窃取任务的线程永远从双端队列的尾部拿任务执行。
工作窃取算法的优点是充分利用线程进行并行计算,并减少了线程间的竞争,其缺点是在某些情况下还是存在竞争,比如双端队列里只有一个任务时。并且消耗了更多的系统资源,比如创建多个线程和多个双端队列。
6.4.3 Fork/Join 模拟案例
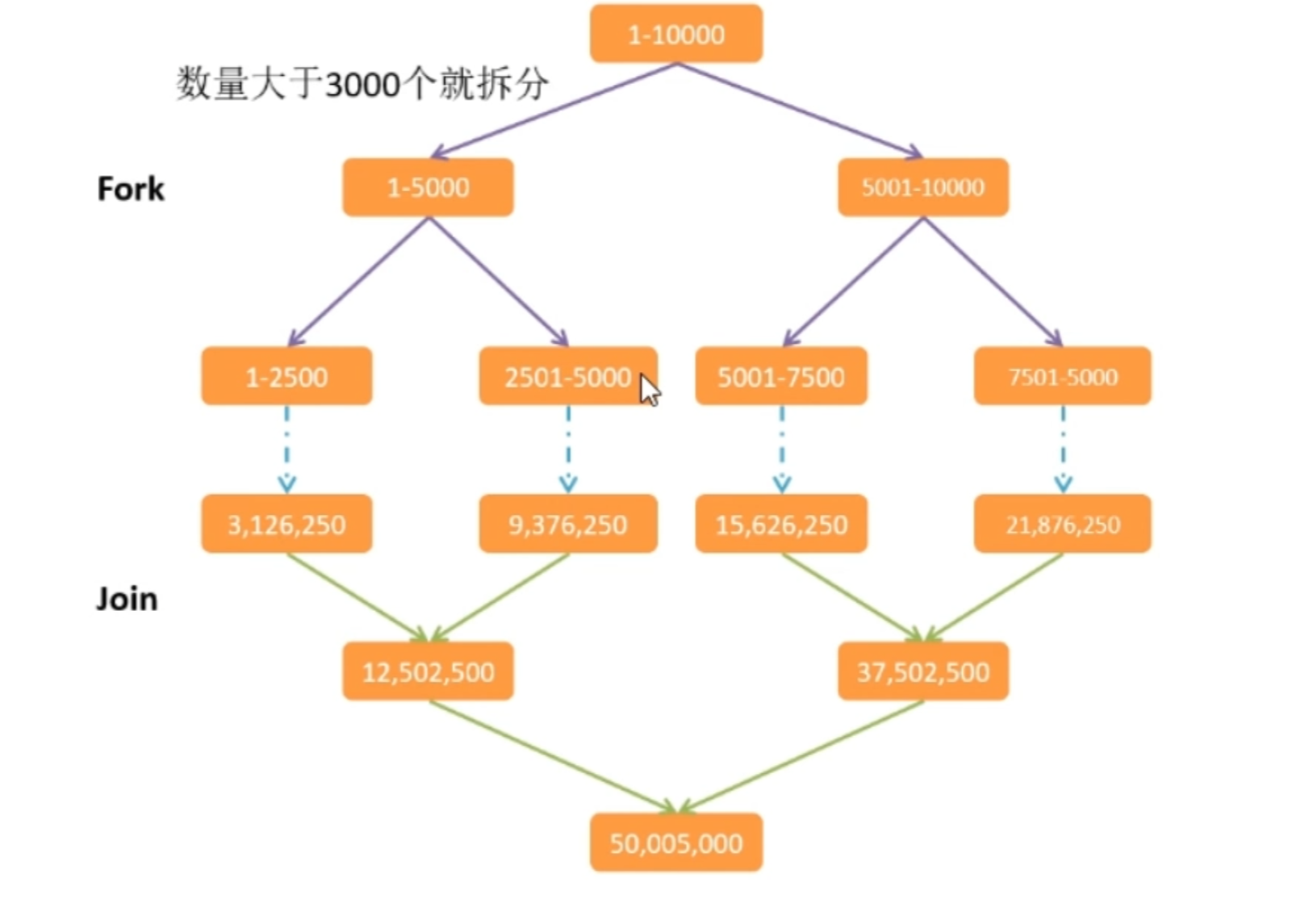
使用 Fork/Join计算1-10000的和,当一个任务的计算数量大于3000的时候拆分任务。数量小于3000的时候就计算
案例实现
public class ParallelStream09ForkJoin {
/**
* 使用 Fork/Join计算1-10000的和, 当一个任务的计算数量大于3000的时候拆分任务。数 量小于3000的时候就计算
*
* @param args
*/
public static void main(String[] args) {
long startTime = System.currentTimeMillis();
ForkJoinPool forkJoinPool = new ForkJoinPool();
SumTask sumTask = new SumTask(1, 10000L);
Long result = forkJoinPool.invoke(sumTask);
System.out.println("result = " + result);
long endTime = System.currentTimeMillis();
System.out.println("总共耗时:" + (endTime - startTime));
}
}
class SumTask extends RecursiveTask<Long> {
//定义一个拆分的临界值
private static final long THRESHOLD = 3000L;
//起始坐标
private final long start;
//尾部坐标
private final long end;
public SumTask(long start, long end) {
this.start = start;
this.end = end;
}
@Override
protected Long compute() {
long length = end - start;
if (length <= THRESHOLD) {
//长度小于临界值, 不需要再做拆分,直接进行计算
long sum = 0;
for (long i = start; i <= end; i++) {
sum += i;
}
System.out.println("计算: " + start + "--" + end + " 的结果为" + sum);
return sum;
} else {
//长度大于临界值, 还需要再做拆分
long middle = (start + end) / 2;
System.out.println("拆分: 左边" + start + "-->" + middle + ", 右边: " + (middle + 1) + "-->" + end);
SumTask left = new SumTask(start, middle);
left.fork(); //拆分
SumTask right = new SumTask(middle + 1, end);
right.fork(); //拆分
return left.join() + right.join(); // 合并
}
}
}
输出:
拆分: 左边1-->5000, 右边: 5001-->10000
拆分: 左边1-->2500, 右边: 2501-->5000
拆分: 左边5001-->7500, 右边: 7501-->10000
计算: 5001--7500 的结果为15626250
计算: 7501--10000 的结果为21876250
计算: 1--2500 的结果为3126250
计算: 2501--5000 的结果为9376250
result = 50005000
总共耗时:3
- 高效使用并行流
- 在考虑选择顺序流还是并行流时,第一个也是最重要的建议就是用适当的基准来检查其性能。
- 留意装箱。自动装箱和拆箱操作会大大降低性能。Java 8中有原始类型流(IntStream、LongStream、DoubleStream)来避免这种操作,但凡有可能都应该用这些流。
- 有些操作本身在并行流上的性能就比顺序流差。特别是limit和findFirst等依赖于元素顺序的操作,它们在并行流上执行的代价非常大。例如,findAny会比findFirst性能好,因为它不一定要按顺序来执行。你总是可以调用unordered方法来把有序流变成无序流。那么,如果你需要流中的n个元素而不是专门要前n个的话,对无序并行流调用limit可能会比单个有序流(比如数据源是一个List)更高效。
- 还要考虑流的操作流水线的总计算成本。设N是要处理的元素的总数,Q是一个元素通过流水线的大致处理成本,则N*Q就是这个对成本的一个粗略的定性估计。Q值较高就意味着使用并行流时性能好的可能性比较大。
- 对于较小的数据量,选择并行流几乎从来都不是一个好的决定。并行处理少数几个元素的好处还抵不上并行化造成的额外开销。
- 要考虑流背后的数据结构是否易于分解。例如,ArrayList的拆分效率比LinkedList高得多,因为前者用不着遍历就可以平均拆分,而后者则必须遍历。另外,用range工厂方法创建的原始类型流也可以快速分解。
- 流自身的特点,以及流水线中的中间操作修改流的方式,都可能会改变分解过程的性能。例如,一个SIZED流可以分成大小相等的两部分,这样每个部分都可以比较高效地并行处理,但筛选操作可能丢弃的元素个数却无法预测,导致流本身的大小未知。
- 还要考虑终端操作中合并步骤的代价是大是小(例如Collector中的combiner方法)。如果这一步代价很大,那么组合每个子流产生的部分结果所付出的代价就可能会超出通过并行流得到的性能提升。
六. Optional工具类
每个Java卡法人员都遇到过: 调用一个方法得到了返回值却不能直接将返回值作为参数去调用别的方法。我们首先要判断这个返回值是否为null,只有在非空的前提下才能将其作为其他方法的参数。否则就会出现NPE异常,就是传说中的空指针异常。
Optional 类主要解决的问题是臭名昭著的空指针异常(NullPointerException) —— 每个 Java 程序员都非常了解的异常。
1.JDK8以前对 null 值得处理
public static void main(String[] args) {
//下面的代码编译不会报错, 但是在运行的时候会抛出空指针异常
String str = null;
int length = str.length();
System.out.println("字符串的长度 = " + length);
}
Exception in thread "main" java.lang.NullPointerException //空指针异常
at com.abin.optional.Optional01Test.main(Optional01Test.java:12)
JDK7 以前对上诉代码的解决方法:
public static void main(String[] args) {
//jdk7以前对null的原始操作
String str = null;
int length;
if (str != null) { //手动去判断
length = str.length();
} else {
length = -1; //-1表示字符串为null
}
System.out.println("字符串的长度 = " + length);
}
使用Optional类:
System.out.println(Optional.ofNullable(str).map(String::length).orElse(0));
在以下示例中,如果我们需要确保不触发异常,就得在访问每一个值之前对其进行明确地检查:
1
2
3
4
5
6
7
8
9
10
11
if (user != null) {
Address address = user.getAddress();
if (address != null) {
Country country = address.getCountry();
if (country != null) {
String isocode = country.getIsocode();
if (isocode != null) {
isocode = isocode.toUpperCase();
}
}
}
可以看到上诉代码很容易就变得冗长,难以维护. 为了简化这个过程,于是诞生了Optional类
2.Optional类的基本使用
2.1 Optional基本概念
Optional 类是一个可以为null的容器对象。如果值存在则isPresent()方法会返回true,调用get()方法会返回该对象。
Optional 是个容器:它可以保存类型T的值,或者仅仅保存null。Optional提供很多有用的方法,这样我们就不用显式进行空值检测。
Optional 类的引入很好的解决空指针异常。

本质上,这是一个包含有可选值的包装类,这意味着 Optional 类既可以含有对象也可以为空。
public final class Optional<T> { //final class 没有子类
/**
* Common instance for {@code empty()}.
*/
private static final Optional<?> EMPTY = new Optional<>();
/**
* If non-null, the value; if null, indicates no value is present
*/
private final T value;
/**
* Constructs an empty instance.
*
* @implNote Generally only one empty instance, {@link Optional#EMPTY},
* should exist per VM.
*/
private Optional() {
this.value = null;
}
........
2.2 Optional对象的创建方式:
- 第一种方式: of() 方法, of方法不支持 null, 否则将抛出NullPointerException
- 第二种方式: ofNullable() 方法, ofNullable支持null
- 第三种方式: empty() 方法, empty直接创建一个空的Optional对象
public static void main(String[] args) {
Person person = new Person();
Person p1 = null;
// 第一种方法: of()方法, of方法不支持 null, 否则将抛出NullPointerException
Optional<Person> op1 = Optional.of(person);
System.out.println("op1 = " + op1.get());
//Optional<Person> op = Optional.of(p1); 抛出NullPointerException
//第二种方式: ofNullable方法, 支持null
Optional<Person> op2 = Optional.ofNullable(person);
Optional<Object> op3 = Optional.ofNullable(null);
//第三种方式: 使用 empty() 方法, 直接创建一个空的Optional对象
Optional<Object> empty = Optional.empty();
}
你可以使用 of() 和 ofNullable() 方法创建包含值的 Optional。两个方法的不同之处在于如果你把 null 值作为参数传递进去,of() 方法会抛出 NullPointerException:
2.3 Optional的常用方法
| 方法名 | 作用 |
|---|---|
| **static |
返回空的 Optional 实例。 |
| **static |
返回一个指定非null值的Optional。 |
| **static |
如果为非空,返回 Optional 描述的指定值,否则返回空的 Optional。 |
| T get() | 如果在这个Optional中包含这个值,返回值,否则抛出异常:NoSuchElementException |
| boolean isPresent() | 如果值存在则方法会返回true,否则返回 false。 |
| void ifPresent(Consumer<? super T> consumer) | 如果值存在则使用该值调用 consumer , 否则不做任何事情。没有返回值 |
| T orElse(T other) | 如果Optional中包含值,返回值, 否则返回 other 默认值。 |
| T orElseGet(Supplier<? extends T> other) | 如果Optional中包含值,返回值, 否则触发 other,并返回 other 调用的结果。 |
| **Optional map(Function<? super T,? extends U> mapper)** | 如果有值,则对其执行调用映射函数得到返回值。如果返回值不为 null,则创建包含映射返回值的Optional作为map方法返回值,否则返回空Optional。 |
| 如果Optional中包含值,返回包含的值,否则抛出由 Supplier 继承的异常 |
-
get() 方法
get()方法: 如果Optional对象中有值, 则返回该值, 如果没有值则抛出NoSuchElementException异常
public T get() { //JDK源码 if (value == null) { throw new NoSuchElementException("No value present"); } return value; }测试:
public static void main(String[] args) { Person person = new Person(); Person p1 = null; Optional<Person> op1 = Optional.of(person); Optional<Object> empty = Optional.empty(); System.out.println("op1.get() = " + op1.get()); //获取person的值 System.out.println("empty.get() = " + empty.get()); //抛异常 }输出:
op1.get() = Person(name=null, age=null) Exception in thread "main" java.util.NoSuchElementException: No value present at java.util.Optional.get(Optional.java:135) at com.abin.optional.Optional03Test.main(Optional03Test.java:20) -
isPresent() 方法
isPresent()方法: 判断Optional对象中是否有值, 有值返回true, 为null返回false
public boolean isPresent() { //JDK源码 return value != null; }测试:
public static void main(String[] args) { Person person1 = new Person(); Person person2 = null; Optional<Person> op1 = Optional.of(person1); Optional<Person> op2 = Optional.empty(); if (op1.isPresent()) { System.out.println("op1.get() = " + op1.get()); } else { System.out.println("op1 是一个空Optional对象"); } if (op2.isPresent()) { System.out.println("op2.get() = " + op2.get()); } else { System.out.println("op2 是一个空Optional对象"); } }输出:
op1.get() = Person(name=null, age=null) op2 是一个空Optional对象 -
orElse(T t)方法
orElse(T t) 方法表示: 如果Optional对象有值则直接返回值, 若为null 则返回orElse的参数 t 默认值;
public T orElse(T other) { //JDK源码 return value != null ? value : other; }测试:
public static void main(String[] args) { Person person = new Person(); Optional<Person> op1 = Optional.of(person); Optional<Person> op2 = Optional.empty(); Person person1 = op1.orElse(new Person("张三", 18)); Person person2 = op2.orElse(new Person("李四", 20)); System.out.println("person1 = " + person1); System.out.println("person2 = " + person2); }输出:
1 2
person1 = Person(name=null, age=null) person2 = Person(name=李四, age=20)
-
orElseGet(Supplier s) 方法
orElseGet(Supplier s) 方法 表示: 如果Optional对象有值则直接返回值, 若为null 则返回Supplier s 的返回值;
public T orElseGet(Supplier<? extends T> other) { //JDK源码 return value != null ? value : other.get(); }测试:
public static void main(String[] args) { Person person = new Person(); Optional<Person> op1 = Optional.of(person); Optional<Person> op2 = Optional.empty(); Person person1 = op1.orElseGet(() -> { System.out.println("默认操作pppp1"); return new Person("test", 20); }); Person person2 = op2.orElseGet(() -> { System.out.println("默认操作pppp2"); return new Person("test", 10); }); System.out.println("person1 = " + person1); System.out.println("person2 = " + person2); }输出:
默认操作pppp2 person1 = Person(name=null, age=null) person2 = Person(name=test, age=10)- orElse() 和 orElseGet() 的不同之处
乍一看,这两种方法似乎起着同样的作用。然而事实并非如此。我们创建一些示例来突出二者行为上的异同。
public class Optional09Test { public static void main(String[] args) { //演示orElse和orElseGet 的区别 Person person = new Person("ZhangSan", 18); Person nullPerson = null; // 空Optional System.out.println("都传入空的Optional对象-----"); System.out.println("orElse方法"); Person res01 = Optional.ofNullable(nullPerson).orElse(createPerson()); System.out.println("获得的值: " + res01); System.out.println("orElseGet方法"); Person res02 = Optional.ofNullable(nullPerson).orElseGet(() -> createPerson()); System.out.println("获得的值: " + res02); System.out.println("++++++++++++++++++++++++++++++++"); // 不为空的Optional System.out.println("都传入有值的Optional对象-----"); System.out.println("orElse方法"); Person res03 = Optional.of(person).orElse(createPerson()); System.out.println("获得的值: " + res03); System.out.println("orElseGet方法"); Person res04 = Optional.ofNullable(person).orElseGet(() -> createPerson()); System.out.println("获得的值: " + res04); } public static Person createPerson() { System.out.println("$$创建默认的人员$$"); return new Person("default", 18); } }输出:
都传入空的Optional对象----- orElse方法 $$创建默认的人员$$ 获得的值: Person{name='default', age=18, height=null} orElseGet方法 $$创建默认的人员$$ 获得的值: Person{name='default', age=18, height=null} ++++++++++++++++++++++++++++++++ 都传入有值的Optional对象----- orElse方法 $$创建默认的人员$$ // 这里传入的是有值的Optional对象, orElse方法仍然执行了createPerson()方法, 虽然返回值是正确的 获得的值: Person{name='ZhangSan', age=18, height=null} orElseGet方法 获得的值: Person{name='ZhangSan', age=18, height=null}结论: 这个示例中,两个 Optional 对象都包含非空值,两个方法都会返回对应的非空值。看似没有任何问题
不过,orElse() 方法仍然创建了 Person 对象。与之相反,orElseGet() 方法不创建 Person对象。
在执行较密集的调用时,比如调用 Web 服务或数据查询,这个差异会对性能产生重大影响。
-
ifPresent()方法
ifPresent(Consumer c) 表示: Optional对象如果存在值, 就执行 Consumer 里面的代码, 如果不存在就不执行 Consumer 里面的代码
public void ifPresent(Consumer<? super T> consumer) { //JDK源码 if (value != null) consumer.accept(value); }测试:
public static void main(String[] args) { Optional<String> s = Optional.of("张三"); Optional<Object> empty = Optional.empty(); s.ifPresent(i -> { System.out.println("存在执行的操作1111 " + i); }); empty.ifPresent(i -> { System.out.println("存在执行的操作2222 " + i); }); }输出:
存在执行的操作1111 张三 //只有一个存在值得才会执行ifPresent里面的Consumer -
map()方法
map( Function f )方法表示对数据进行一些特定的操作: 如果存在值,则就对其执行传入的 Lambda 表达式,如果结果为非空,则返回一个描述结果的非空Optional对象。否则返回一个空的Optional对象。
map() 对值应用(调用)作为参数的函数,然后将返回的值包装在Optional中, 这就使对返回值进行链试调用的操作成为可能
//If a value is present, apply the provided mapping function to it, and if the result is non-null, return an Optional describing the result. Otherwise return an empty Optional. public<U> Optional<U> map(Function<? super T, ? extends U> mapper) { Objects.requireNonNull(mapper); if (!isPresent()) return empty(); else { return Optional.ofNullable(mapper.apply(value)); } }测试:
public class Optional08TestMap { public static void main(String[] args) { Person person = new Person(null, 18); String upperName = getUpperName(person); System.out.println(upperName); } public static String getUpperName(Person p) { Optional<Person> person = Optional.ofNullable(p); //先将参数存放在Optional容器中 if (person.isPresent()) { return person.map(s -> s.getName()) .map(s -> s.toUpperCase()) .orElse("警告: p.name为null"); } else { //如果Optional对象person 为null执行以下的操作 return null; } } } 输出: 警告: p.name为nullpublic class Optional08TestMap { public static void main(String[] args) { Person person = new Person("ZhangSan", 18); String upperName = getUpperName(person); System.out.println(upperName); } public static String getUpperName(Person p) { Optional<Person> person = Optional.ofNullable(p); //先将参数存放在Optional容器中 if (person.isPresent()) { //如果Optional对象person 存在值执行以下的操作 return person.map(Person::getName) //获取name .map(String::toUpperCase) //将name转化为大写 .orElse("警告: p.name为null"); //为null就返回参数内容 } else { //如果Optional对象person 为null执行以下的操作 return null; } } } 输出: ZHANGSAN
Optional 细节: https://blog.csdn.net/wwe4023/article/details/80760416#:~:text=Optional%20%E7%B1%BB%E4%B8%BB%E8%A6%81%E8%A7%A3%E5%86%B3%E7%9A%84%E9%97%AE%E9%A2%98%E6%98%AF%E8%87%AD%E5%90%8D%E6%98%AD%E8%91%97%E7%9A%84%E7%A9%BA%E6%8C%87%E9%92%88%E5%BC%82%E5%B8%B8%EF%BC%88NullPointerException%EF%BC%89%20%E2%80%94%E2%80%94%20%E6%AF%8F%E4%B8%AA%20Java%20%E7%A8%8B%E5%BA%8F%E5%91%98%E9%83%BD%E9%9D%9E%E5%B8%B8%E4%BA%86%E8%A7%A3%E7%9A%84%E5%BC%82%E5%B8%B8%E3%80%82.%20%E6%9C%AC%E8%B4%A8%E4%B8%8A%EF%BC%8C%E8%BF%99%E6%98%AF%E4%B8%80%E4%B8%AA%E5%8C%85%E5%90%AB%E6%9C%89%E5%8F%AF%E9%80%89%E5%80%BC%E7%9A%84%E5%8C%85%E8%A3%85%E7%B1%BB%EF%BC%8C%E8%BF%99%E6%84%8F%E5%91%B3%E7%9D%80%20Optional,%E7%9A%84%E6%84%8F%E4%B9%89%E6%98%BE%E7%84%B6%E4%B8%8D%E6%AD%A2%E4%BA%8E%E6%AD%A4%E3%80%82.%20%E6%88%91%E4%BB%AC%E4%BB%8E%E4%B8%80%E4%B8%AA%E7%AE%80%E5%8D%95%E7%9A%84%E7%94%A8%E4%BE%8B%E5%BC%80%E5%A7%8B%E3%80%82.%20%E5%9C%A8%20Java%208%20%E4%B9%8B%E5%89%8D%EF%BC%8C%E4%BB%BB%E4%BD%95%E8%AE%BF%E9%97%AE%E5%AF%B9%E8%B1%A1%E6%96%B9%E6%B3%95%E6%88%96%E5%B1%9E%E6%80%A7%E7%9A%84%E8%B0%83%E7%94%A8%E9%83%BD%E5%8F%AF%E8%83%BD%E5%AF%BC%E8%87%B4%20NullPointerException%20%EF%BC%9A.
Java8 之 lambda 表达式、方法引用、函数式接口、默认方式、静态方法: https://blog.csdn.net/lzb348110175/article/details/103806112